
auto-bench: Benchmarking Quantized LLMs for Local Coding Agents
New open LLMs are released constantly and keep improving. Gemma 4 was recently claimed to be groundbreaking, but when I tried the quantized version for coding agents like opencode, it was completely unusable—it gets stuck in output loops or unable to call tools with correct syntax. This is the norm, not an exception. Most quantized open LLMs I try for agentic AI simply don't work. Finding a setup that does requires trial and error across model, quantization, and dozens of settings.
I just want a command I can run to get a working LLM for my GPU. No hours of experimentation. No guessing at combinations. Just a proven setup. I couldn't find one, so I built auto-bench.
auto-bench
Auto-bench is a tool that allows you to define experiments, automatically run LLM inference servers with the proper settings, and execute a set of benchmarks against them. Rather than reinventing the wheel, I'm currently using Harbor Framework to run the tests. Auto-bench has first-class support for quantized models. This is important, because most existing benchmarks and leaderboards don't consider quantization, even though that is how many people run models.
My project is in its earliest stages, but I have at least one experiment to share: testing various quantizations of the Qwen3.5-2B model on a single problem instance from SWE-bench Verified (swe-bench/sympy__sympy-22914). I deliberately selected an easy instance to see if quantized models can perform basic tool calls to solve an easy problem.
Here is how this experiment is configured in auto-bench:
# Benchmark 22 quants of Qwen3.5-2B on a single SWE-bench instance
# Usage: auto-bench run configs/qwen-2b-quant-sweep.yaml
name: qwen-2b-quant-sweep
backend_type: llamacpp
dataset: SWE-bench/SWE-bench_Verified
instance_ids:
- swe-bench/sympy__sympy-22914
model:
name: Qwen3.5-2B
source: huggingface
repo_id: unsloth/Qwen3.5-2B-GGUF
sweep:
- label: BF16
filename: Qwen3.5-2B-BF16.gguf
- label: Q3_K_S
filename: Qwen3.5-2B-Q3_K_S.gguf
- label: Q5_K_M
filename: Qwen3.5-2B-Q5_K_M.gguf
- label: Q5_K_S
filename: Qwen3.5-2B-Q5_K_S.gguf
- label: Q6_K
filename: Qwen3.5-2B-Q6_K.gguf
# ... 17 more quantizations
sampling:
temperature: 0.7
top_p: 0.8
top_k: 20
min_p: 0.0
presence_penalty: 1.5
repetition_penalty: 1.0
agent:
agent: openhands
env: docker
attempts: 4
limit: 1
setup_multiplier: 10.0
evaluation:
run_evaluation: truePart of my goal is to include all information needed to actually run the models properly. For example, the sampling section includes the sampling parameters that are recommended by Qwen for best performance, and these types of details can make a huge effect! My vision is to eventually have a leaderboard that will provide you with a llama.cpp command-line to run the model with the proper settings, and then you can just copy and paste that command to get a working LLM for your coding agent.
Results
Before diving into the data, here's what the columns mean:
- Resolved: Number of problem instances successfully resolved by the agent
- Total: Total number of attempts (8 in this case)
- % Resolved: Resolution rate as a percentage
- PPL (Perplexity): Measures the model's confidence in its predictions. Lower is generally better, though surprisingly this doesn't always correlate with task success
- KL: Kullback-Leibler divergence—how much the quantized model's output distribution diverges from the original model's. Lower is better, but as we'll see, it's not a strong predictor of task performance
- Runtime: Total time to run all attempts
- Exceptions: Types of errors encountered (e.g., timeouts, exit code errors)
| Quant | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 0/8 | 0% | 13.38 | — | 3m 37s | — |
| IQ4_NL | 1/8 | 12.5% | 13.67 | 0.0309 | 3m 53s | — |
| IQ4_XS | 0/8 | 0% | 13.68 | 0.0318 | 51m 53s | Timeout, ExitCode |
| Q3_K_M | 2/8 | 25% | 14.33 | 0.0774 | 51m 48s | Timeout |
| Q3_K_S | 5/8 | 62.5% | 15.08 | 0.1334 | 51m 39s | Timeout |
| Q4_0 | 4/8 | 50% | 13.91 | 0.0454 | 19m 5s | — |
| Q4_1 | 3/8 | 37.5% | 13.68 | 0.0273 | 11m 14s | — |
| Q4_K_M | 1/8 | 12.5% | 13.79 | 0.0230 | 4m 8s | ExitCode |
| Q4_K_S | 2/8 | 25% | 13.78 | 0.0274 | 4m 43s | — |
| Q5_K_M | 8/8 | 100% | 13.46 | 0.0082 | 51m 48s | Timeout |
| Q5_K_S | 6/8 | 75% | 13.49 | 0.0100 | 8m 53s | — |
| Q6_K | 7/8 | 87.5% | 13.48 | 0.0035 | 51m 54s | Timeout |
| Q8_0 | 4/8 | 50% | 13.39 | 0.0012 | 51m 49s | Timeout |
| UD-IQ2_M | 0/8 | 0% | 17.61 | 0.2677 | 51m 56s | Timeout(5) |
| UD-IQ2_XXS | 0/8 | 0% | 27.11 | 0.7018 | 51m 58s | Timeout(6), ExitCode |
| UD-IQ3_XXS | 0/8 | 0% | 15.31 | 0.1549 | 51m 49s | Timeout |
| UD-Q2_K_XL | 0/8 | 0% | 17.15 | 0.2388 | 51m 49s | Timeout(2) |
| UD-Q3_K_XL | 6/8 | 75% | 13.94 | 0.0520 | 51m 56s | Timeout(2) |
| UD-Q4_K_XL | 6/8 | 75% | 13.60 | 0.0164 | 7m 40s | — |
| UD-Q5_K_XL | 8/8 | 100% | 13.51 | 0.0077 | 18m 2s | — |
| UD-Q6_K_XL | 3/8 | 37.5% | 13.48 | 0.0020 | 6m 51s | — |
| UD-Q8_K_XL | 3/8 | 37.5% | 13.37 | 0.0011 | 5m 49s | — |
| vllm | 1/8 | 12.5% | — | — | 6m 32s | — |
The Base Model Is Broken
The most striking finding is that the unquantized base model (shown as vllm in the results) achieves only 12.5% resolution—worse than most quantized versions. BF16, which is nearly the original model without quantization, also consistently fails at 0%. This suggests the base model is fundamentally broken for this coding task, but quantization somehow fixes it.
Many medium-sized quantizations (Q5_K_M, UD-Q5_K_XL, Q6_K) achieve 100%, 100%, and 87.5% resolution respectively. Yet larger quantizations like Q8_0 fail again at 50%. This isn't about bigger being better—it's about finding the quantization that repairs the base model's broken reasoning.
KL Divergence Doesn't Predict Success
The KL (Kullback-Leibler) divergence column measures how much a quantized model's output distribution diverges from the original. If the base model is broken for this task, then staying close to the original (low divergence) just means inheriting the same brokenness. That could explain why there's no strong correlation between divergence and success.
Q5_K_M achieves 100% resolution with low divergence (0.0082)—but so does UD-Q5_K_XL with similar low divergence. Meanwhile, BF16 (essentially 0 divergence, nearly the original) fails completely at 0%. Some high-divergence models like UD-IQ2_XXS fail too, but others like Q3_K_S achieve 62.5% with divergence of 0.1334.
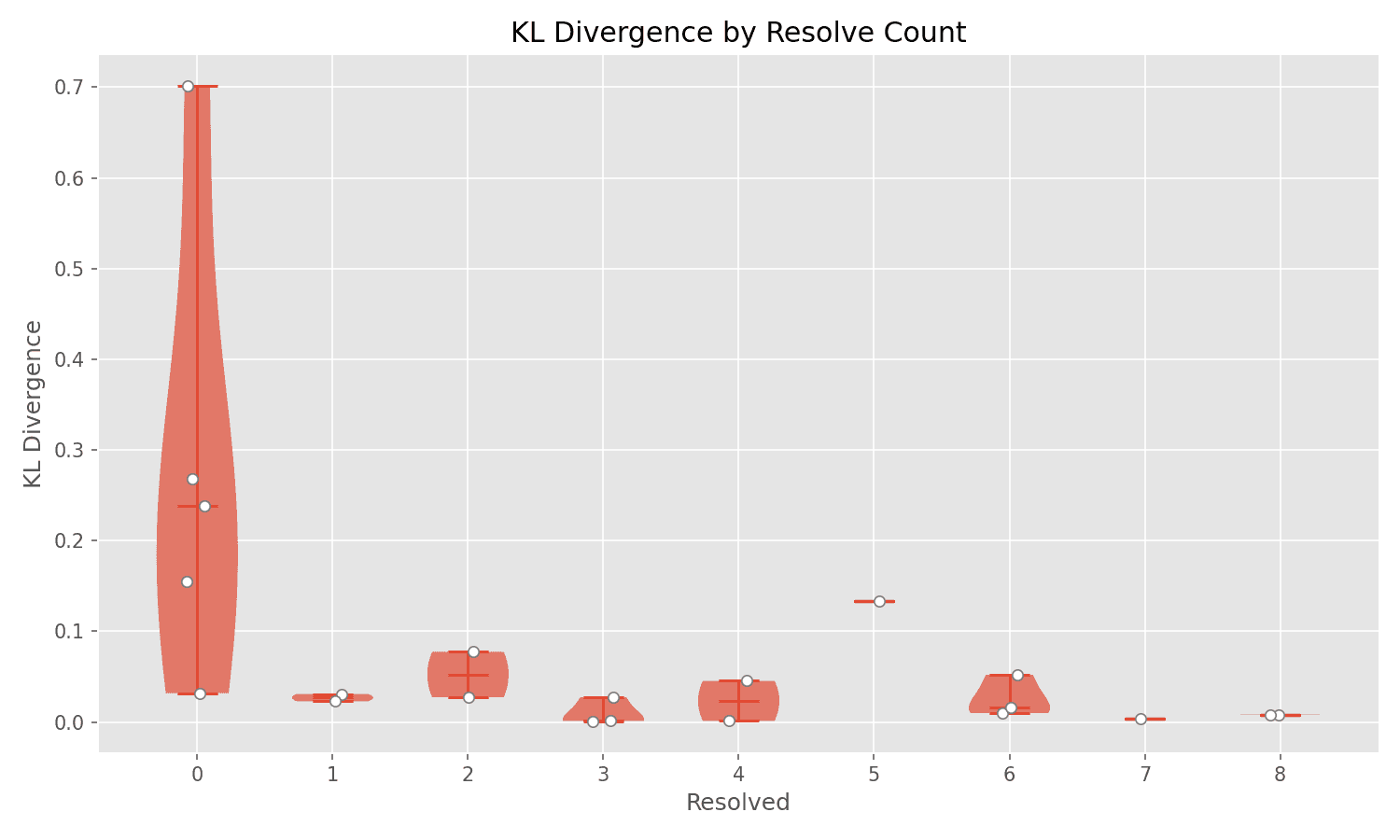
The plot tells the story: failing models (0 resolved) scatter across the entire divergence range—some very close to the original, some far away. If you stayed loyal to a broken base model, you'd fail. If you accidentally diverged in the right way, you'd succeed. KL divergence alone can't tell you which happened.
Multiple Failure Modes
There are two distinct failure modes visible in the results.
Failure Mode 1: Infinite Loops (AgentTimeoutError)
Many quantizations exhibit infinite looping behavior, where the agent gets stuck generating the same outputs repeatedly and eventually hits the timeout limit. Models like UD-IQ2_M, UD-IQ2_XXS, IQ4_XS, and IQ3_XXS show multiple AgentTimeoutError instances. Interestingly, this failure mode appears to correlate strongly with extremely aggressive quantization (e.g., IQ2 variants with very high KL divergence > 0.26).
Failure Mode 2: Silent Failure
The second failure mode is when the agent runs to completion without timing out, but simply fails to correctly solve the problem. Models like BF16, UD-IQ2_XXS, and UD-IQ3_XXS never produce output loops, but they still achieve 0% resolution. This suggests that the quantization has degraded the model's reasoning ability below a critical threshold where it can't effectively reason about code, even if it's still syntactically generating valid tool calls.
Conclusion: The Base Model Is Broken, Quantization Fixes It
The core finding is that the unquantized base model (12.5% resolution) and near-original BF16 (0% resolution) both fail for this coding task. Yet specific quantizations like Q5_K_M and UD-Q5_K_XL achieve 100%. Quantization isn't degrading a working model—it's repairing a broken one.
Notice in the visualization: models that fail (0 resolved) scatter across the entire KL divergence range, from very close to the original all the way to extremely divergent. Models that succeed tend to cluster at low divergence. But the scatter on the left side proves you can't predict failure from divergence—some quantizations stay very close to the original yet still fail.
The lesson is that model quality for coding agents is challenging to predict. This is why auto-bench exists—to empirically measure what actually works for your specific use case.
Open Questions and Limitations
This experiment demonstrates an interesting phenomenon, but it's based on a single problem instance from a single model family. The findings should be interpreted with appropriate caution:
- Generalization to other models: Do these patterns hold for Llama, Mistral, or other model families? The behaviors might be Qwen-specific.
- Generalization to other instances: I deliberately chose an easy instance to see if quantized models could work at all. Would the patterns hold on harder instances? SWE-bench Verified spans easy to extremely difficult problems.
- Generalization to other tasks: Would we see similar results on SWE-bench instances beyond Verified, or on other benchmarks like HumanEval or MBPP?
- Sampling parameter sensitivity: How much of the improvement from quantized models comes from properly-tuned sampling parameters? A controlled ablation would be valuable.
I'm actively running experiments to answer these questions! The auto-bench framework is designed to scale to hundreds of model/quantization combinations and thousands of problem instances. Stay tuned for results on larger model families, more problem instances, and more task types.

Powered with by Gatsby 5.0