
Is It a Function or an OO Method?
I've been feeling left behind by all the exciting news surrounding AI, so I've been quietly working on a project to get myself up to speed with some modern Transformers models for NLP. This project is mostly a learning exercise, but I'm sharing it in the hopes that it is still interesting!
Background: Functions, Methods and OOAnalyzer
One of my favorite projects is OOAnalyzer, which is part of SEI's Pharos static binary analysis framework. As the name suggests, it is a binary analysis tool for analyzing object-oriented (OO) executables to learn information about their high level structure. This structure includes classes, the methods assigned to each class, and the relationships between classes (such as inheritance). What's really cool about OOAnalyzer is that it is built on rules written in Prolog -- yes, Prolog! So it's both interesting academically and practically; people do use OOAnalyzer in practice. For more information, check out the original paper or a video of my talk.
Along the way to understanding a program's class hierarchy, OOAnalyzer needs to solve many smaller problems. One of these problems is: Given a function in an executable, does this function correspond to an object-oriented method in the source code? In my humble opinion, OOAnalyzer is pretty awesome, but one of the yucky things about it is that it contains many hard-coded assumptions that are only valid for Microsoft Visual C++ on 32-bit x86 (or just x86 MSVC to save some space!)
It just so happens that on
this compiler and platform, most OO methods use the thiscall calling
convention, which passes a pointer to the this object in the ecx register. Below is an interactive Godbolt example that shows a simple method mymethod being compiled by x86 MSVC. You can see on line 7 that the thisptr is copied from ecx onto the stack at offset -4. On line 9, you can see that arg is passed on the stack. In contrast, on line 20, myfunc only receives its argument on the stack, and does not access ecx.
(Note that this assembly code comes from the compiler and includes the name of functions, which makes it obvious whether a function corresponds to an OO method. Unfortunately this is not the case when reverse engineering without access to source code!)
Because most non-thisptr arguments are passed on the stack in x86 MSVC, but the thisptr is passed in ecx, seeing an argument in the ecx register is highly suggestive (but not definitive) that the function corresponds to an OO
method. OOAnalyzer has a variety of heuristics based on this notion that tries
to determine whether a function corresponds to an OO method. These work well,
but they're specific to x86 MSVC. What if we wanted to
generalize to other compilers? Maybe we could learn to do that. But first,
let's see if we can learn to do this for x86 MSVC.
Learning to the Rescue
Let's play with some machine learning!
Step 1: Create a Dataset
You can't learn without data, so the first thing I had to do was create a dataset. Fortunately, I already had a lot of useful tools and projects for generating ground truth about OO programs that I could reuse.
BuildExes
The first project I used was BuildExes. This is a project that takes several test programs that are distributed as part of OOAnalyzer and builds them with many versions of MSVC and a variety of compiler options. The cute thing about BuildExes is that it uses Azure pipelines to install different versions of MSVC using the Chocolatey package manager and perform the compilations. Otherwise we'd have to install eight MSVC versions, which sounds like a pain to me. BuildExes uses a mix of publicly available Chocolatey packages and some that I created for older versions of MSVC that no one else cares about 🤣.
When BuildExes runs on Azure pipelines, it produces an artifact consisting of a large number of executables that I can use as my dataset.
Ground Truth
As part of our evaluations for the OOAnalyzer paper, we wrote a variety of scripts that extracted ground truth information out of PDB debugging symbols files (which, conveniently, are also included in the BuildExes artifact!) These scripts aren't publicly available, but they aren't top secret and we've shared them with other researchers. They essentially call a tool to decode PDB files into a textual representation and then parse the results.
Putting it Together
Here is the script that produces the ground truth
dataset.
It's a bit obscure, but it's not very complicated. Basically, for each executable in the BuildExes
project, it reads the ground truth file, and also uses the bat-dis
tool from the ROSE Binary
Analysis Framework to
disassemble the program.
The initial dataset is available on 🤗 HuggingFace. Aside: I love that 🤗 HuggingFace lets you browse datasets to see what they look like.
Step 2: Split the Data
The next step is to split the data into training and test sets. In ML, the best practice is generally to ensure that there is no overlap between the training and test sets. This is so that the performance of a model on the test set represents performance on "unseen examples" that the model has not been trained on. But this is tricky for a few reasons.
First, software is natural, which means that we can expect that distinct programmers will naturally write the same code over and over again. If a function is independently written multiple times, should it really count as an "previously seen example"? Unfortunately, we can't distinguish when a function is independently written multiple times or simply copied. So when we encounter a duplicate function, what should we do? Discard it entirely? Allow it to be in both the training and test sets? There is a related question for functions that are very similar. If two functions only differ by an identifier name, would knowledge of one constitute knowledge of the other?
Second, compilers introduce a lot of functions that are not written by the programmer, and thus are very, very common. If you look closely at our dataset, it is actually dominated by compiler utility functions and functions from the standard library. In a real-world setting, it is probably reasonable to assume that an analyst has seen these before. Should we discard these, or allow them to be in both the training and test sets, with the understanding that they are special in some way?
Constructing a training and test split has to take into account these questions. I actually created an additional dataset that splits the data via different mechanisms.
I think the most intuitively correct one is what I call splitting by library
functions. The idea is quite simple. If a function name appears in the
compilation of more than one test program, we call it a library function. For
example, if we compile oo2.cpp and oo3.cpp to oo2.exe and oo3.exe
respectively, and both executables contain a function called
msvc_library_function, then that function is probably introduced by the
compiler or standard library, and we call it a library function. If function
oo2_special_fun only appears in oo2.exe and no other executables, then we
call it a non-library function. We then split the data into training and test
sets such that the training set consists only of library functions, and the test
set consists only of non-library functions. In essence, we train on the commonly
available functions, and test on the rare ones.
This idea isn't perfect, but it works pretty well, and it's easy to understand and justify. You can view this split here.
Step 3: Fine-tune a Model
Now that we have a dataset, we can fine-tune a model. I used the huggingface/CodeBERTa-small-v1 model on 🤗 HuggingFace as a base model. This is a model that was trained on a large corpus of code, but that is not trained on assembly code (and we will see some evidence of this).
My model, which I fine-tuned with the training split using the "by library" method described above, is available as ejschwartz/oo-method-test-model-bylibrary. It attains 94% accuracy on the test set, which I thought was pretty good. I suspect that OOAnalyzer performs similarly well.
If you are familiar with the 🤗 Transformers library, it's actually quite easy to use my model (or someone else's). You can actually click on the "Use in Transformers" button on the model page, and it will show you the Python code to use. But if you're a mere mortal, never fear, as I've created a Space for you to play with, which is embedded here:
If you want, you can upload your own x86 MSVC executable. But if you don't
have one of those lying around, you can just click on one of the built-in example
executables at the bottom of the space (ooex8.exe and
ooex9.exe). From there, you can select a function from the dropdown menu to
see its disassembly, and the model's opinion of whether it is a class method or
not. If the assembly code is too long for the model to process, you'll currently encounter an error.
Here's a recording of what it looks like:
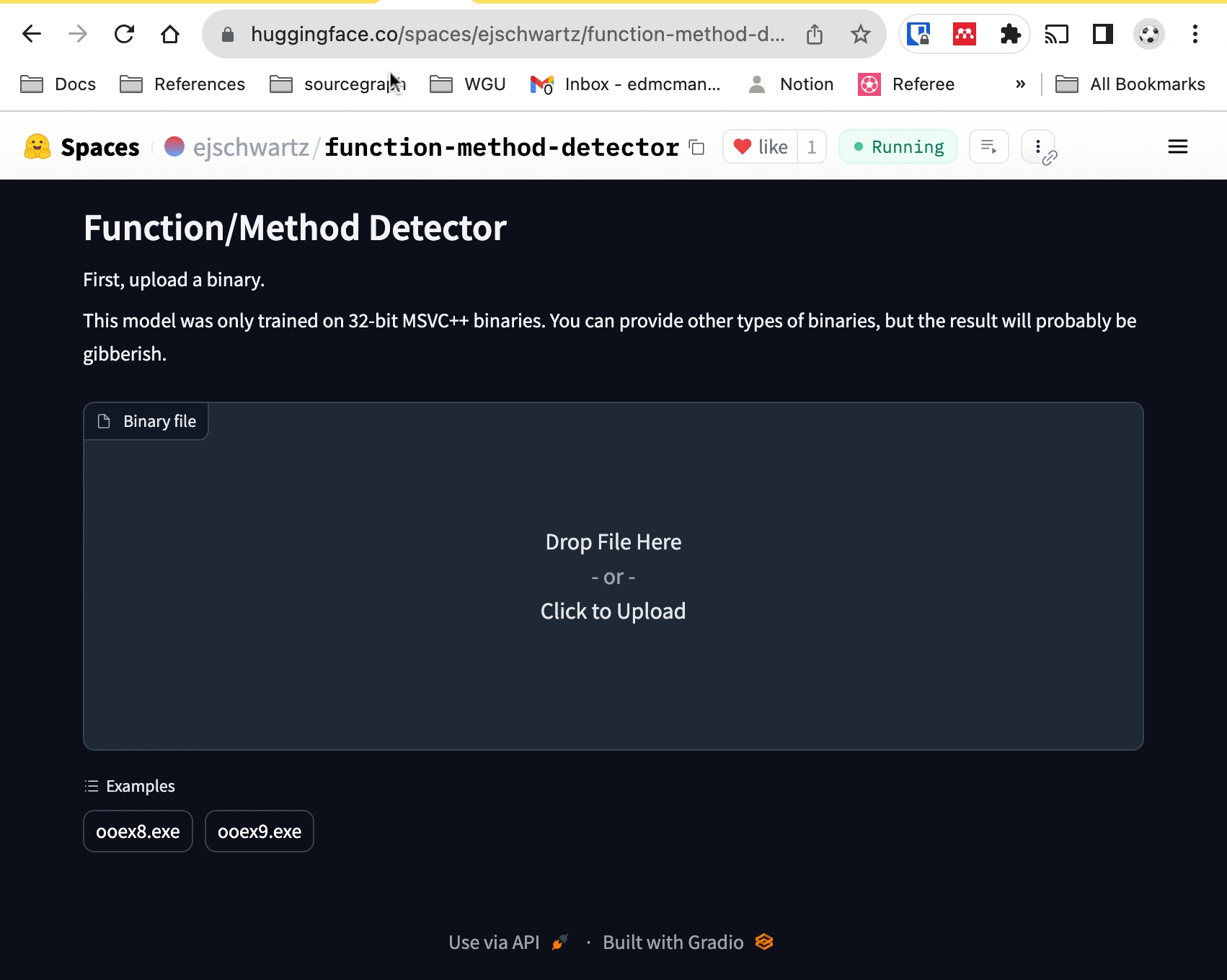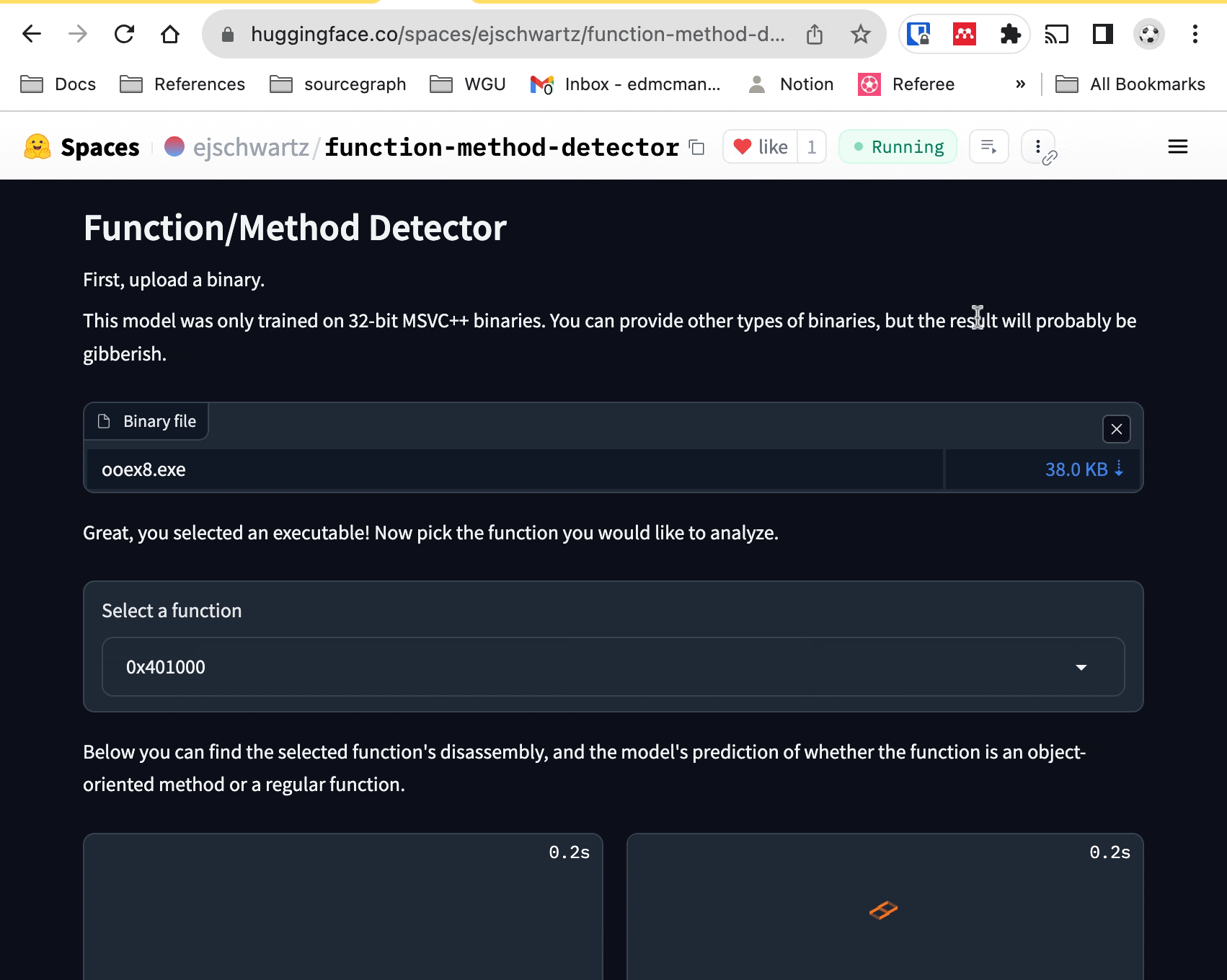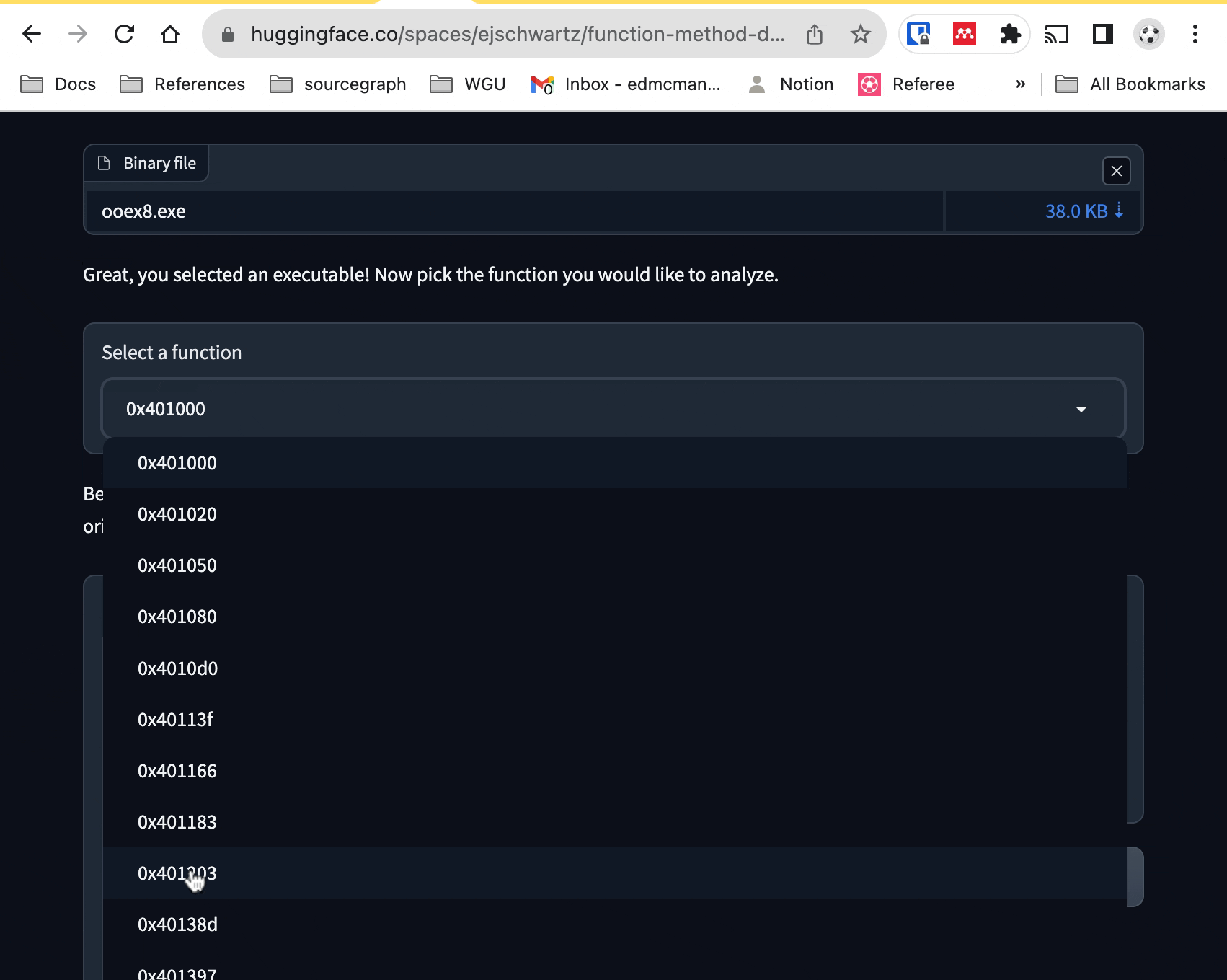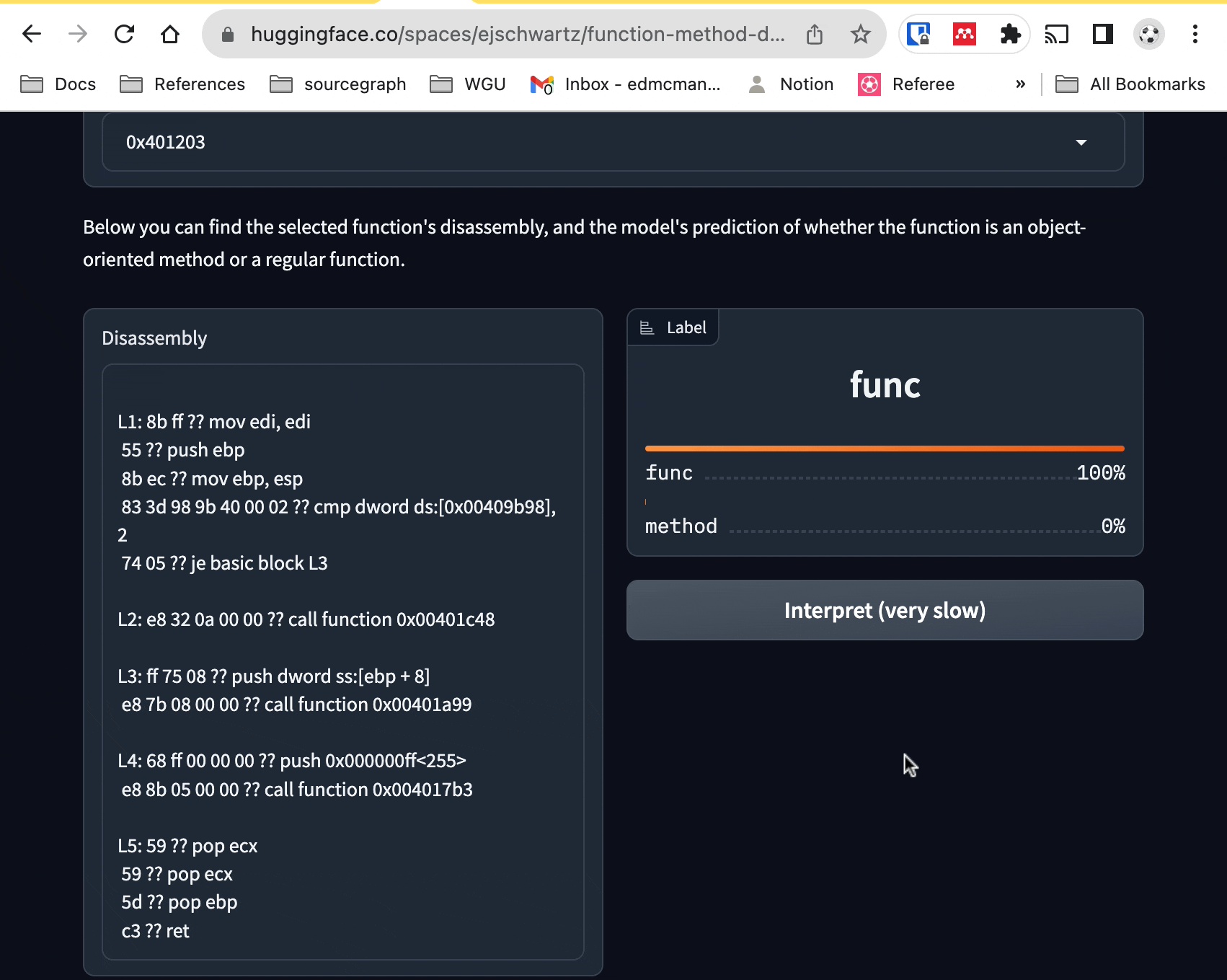
If you are very patient, you can also click on "Interpret" to run Shapley interpretation, which will show which tokens are contributing the most. But it is slow. Very slow. Like five minutes slow. It also won't give you any feedback or progress (sigh -- blame gradio, not me).
Here's an example of an interpretation. The dark red tokens contribute more to
method-ness and dark blue tokens contribute to function-ness. You can also see that
registers names are not tokens in the original CodeBERT model. For instance, ecx
and is split into ec and x, which the model learns to treat as a pair. It's
not a coincidence that the model learned that ecx is indicative of a method,
as this is a rule used in OOAnalyzer as well. It's also somewhat interesting that the model views sequences of zero bytes in the binary code as being indicative of function-ness.

Looking Forward
Now that we've shown we can relearn a heuristic that is already included in OOAnalyzer, this raises a few other questions:
-
One of the "false positives" of the
ecxheuristics is thefastcallcalling convention, which also uses theecxregister. We should ensure that the dataset contains functions with this calling convention (and others), since they do occur in practice. -
What other parts of OOAnalyzer can we learn from examples? How does the accuracy of learned properties compare to the current implementation?
-
Can we learn to distinguish functions and methods for other architectures and compilers? Unfortunately, one bottleneck here is that our ground truth scripts only work for MSVC. But this certainly isn't an insurmountable problem.

Powered with by Gatsby 5.0