
Benchmarking Quantized LLMs for Local Coding Agents Part 2: Testing all instances of SWE-bench Verified
In Part 1, I introduced auto-bench, a tool for benchmarking quantized LLMs for local coding agents, and shared some results from a preliminary study on a single instance from SWE-bench Verified. The results showed that (1) KL Divergence doesn't predict performance, and (2) quantizations can both outperform and underperform the original model.
In this post, I'll share some new results. Like the other experiment, this one
also focuses on Qwen3.5-2B. Unlike the other experiment, which tested a
single instance of SWE-bench Verified with eight
attempts,
this experiment tests all instances of SWE-bench Verified with one
attempt.
Results
Without further ado, here are the results.
| Quant | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 28/500 | 5.6% | 13.38 | — | 547m 59s | Timeout(47), ExitCode(22), Verifier(2) |
| IQ4_NL | 26/500 | 5.2% | 13.67 | 0.0309 | 423m 21s | Timeout(29), ExitCode(16), Verifier(1) |
| IQ4_XS | 24/500 | 4.8% | 13.68 | 0.0318 | 493m 7s | Timeout(39), ExitCode(15), Reward(1), Verifier(2) |
| Q3_K_M | 30/500 | 6.0% | 14.33 | 0.0774 | 785m 43s | Timeout(67), ExitCode(21) |
| Q3_K_S | 20/500 | 4.0% | 15.08 | 0.1334 | 742m 25s | Timeout(73), ExitCode(25), Reward(1), Verifier(1) |
| Q4_0 | 24/500 | 4.8% | 13.91 | 0.0454 | 407m 34s | Timeout(25), ExitCode(21), Verifier(1) |
| Q4_1 | 36/500 | 7.2% | 13.68 | 0.0273 | 766m 19s | Timeout(59), ExitCode(16), Reward(1), Verifier(1) |
| Q4_K_M | 27/500 | 5.4% | 13.79 | 0.0230 | 357m 0s | Timeout(20), ExitCode(23), Verifier(2) |
| Q4_K_S | 19/500 | 3.8% | 13.78 | 0.0274 | 519m 39s | Timeout(38), ExitCode(23), Reward(1), Verifier(1) |
| Q5_K_M | 62/500 | 12.4% | 13.46 | 0.0082 | 784m 58s | Timeout(61), ExitCode(23), Reward(1), Verifier(1) |
| Q5_K_S | 46/500 | 9.2% | 13.49 | 0.0100 | 563m 27s | Timeout(30), ExitCode(25), Reward(1), Verifier(3) |
| Q6_K | 58/500 | 11.6% | 13.48 | 0.0035 | 820m 37s | Timeout(62), ExitCode(20), Verifier(1) |
| Q8_0 | 37/500 | 7.4% | 13.39 | 0.0012 | 598m 13s | Timeout(46), ExitCode(17), Verifier(1) |
| UD-IQ2_M | 1/500 | 0.2% | 17.61 | 0.2677 | 1866m 13s | Timeout(300), ExitCode(24), Verifier(1) |
| UD-IQ2_XXS | 1/500 | 0.2% | 27.11 | 0.7018 | 2196m 49s | Timeout(371), ExitCode(19) |
| UD-IQ3_XXS | 5/500 | 1.0% | 15.31 | 0.1549 | 1481m 24s | Timeout(230), ExitCode(24), Verifier(1) |
| UD-Q2_K_XL | 2/500 | 0.4% | 17.15 | 0.2388 | 442m 51s | Timeout(29), ExitCode(27) |
| UD-Q3_K_XL | 48/500 | 9.6% | 13.94 | 0.0520 | 738m 44s | Timeout(57), ExitCode(19), Reward(1), Verifier(1) |
| UD-Q4_K_XL | 57/500 | 11.4% | 13.60 | 0.0164 | 759m 13s | Timeout(48), ExitCode(18), Reward(2), Verifier(2) |
| UD-Q5_K_XL | 62/500 | 12.4% | 13.51 | 0.0077 | 932m 37s | Timeout(71), ExitCode(18), Reward(2), Verifier(1) |
| UD-Q6_K_XL | 29/500 | 5.8% | 13.48 | 0.0020 | 539m 38s | Timeout(35), ExitCode(20), Verifier(1) |
| UD-Q8_K_XL | 36/500 | 7.2% | 13.37 | 0.0011 | 502m 1s | Setup(1), Timeout(35), ExitCode(23), Verifier(2) |
| vllm | 26/500 | 5.2% | — | — | 521m 14s | Timeout(49), ExitCode(11), Verifier(1) |
And the plot of % Resolved vs KL Divergence:
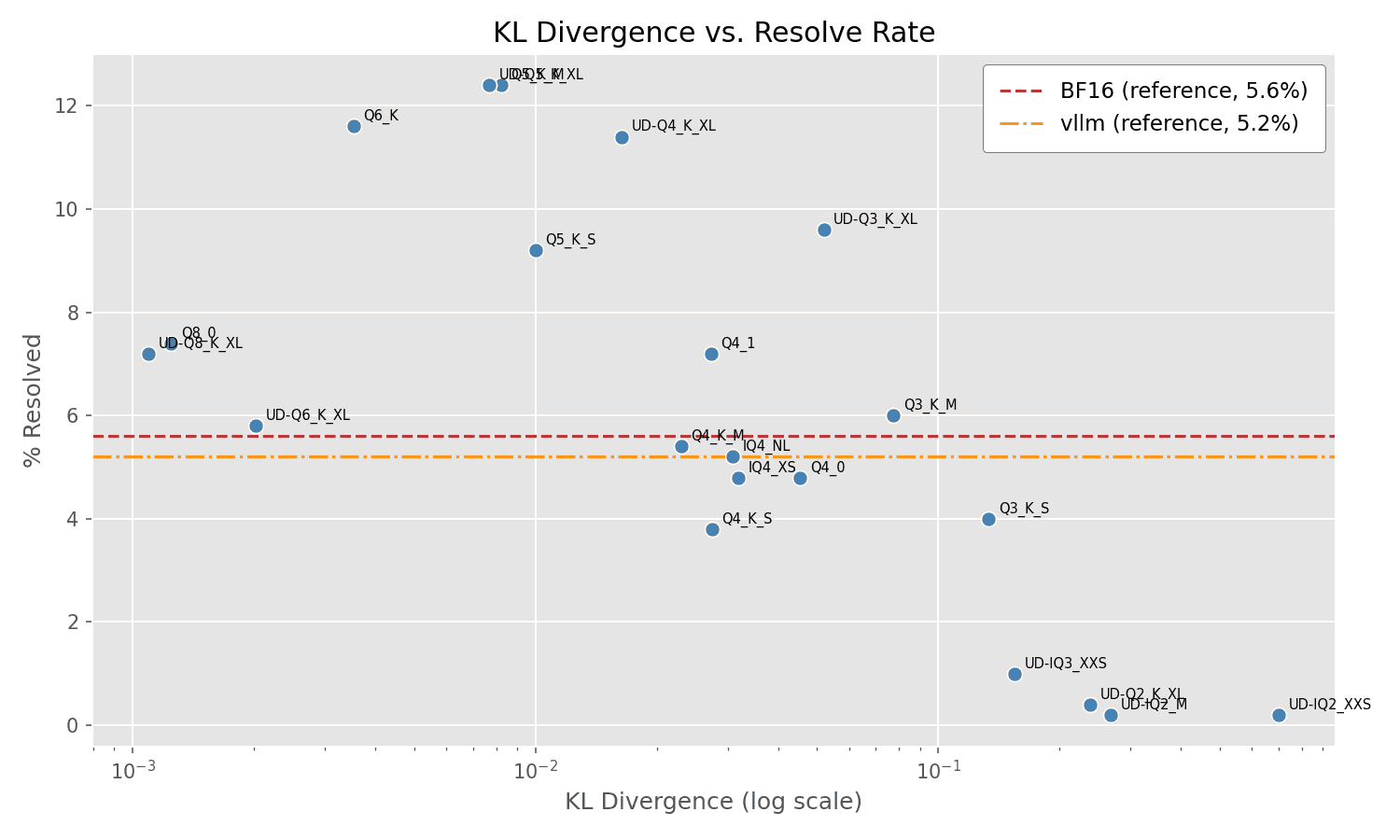
Observations
A few observations:
- The overall resolve rates are low across the board. This is not a very powerful model. I intentionally selected an easy problem instance for the Part 1 experiment.
- As in Part 1, many of the "mid-range" quantizations outperform the original model, yet small and large quantizations underperform. This is consistent with the idea that some quantizations are actually beneficial, while others are harmful.
- Also as in Part 1, KL Divergence does not fully explain performance.
What next?
This experiment largely confirmed the findings from Part 1 about the Qwen3.5-2B model. An open question is whether these results apply to other models as well. I plan to run similar experiments on larger variants of the Qwen3.5 family next, but I won't be evaluating every quantization. Too much time is wasted on bad quantizations because they get stuck in endless loops. Instead, I'll probably try a select few quantizations, such as BF16, Q8_0, and Q5_K_M. Although I am interested in understanding these peculiar behaviors, my primary goal is actually to find which models and quantizations are usable.

Powered with by Gatsby 5.0