
Benchmarking Quantized LLMs for Local Coding Agents Part 3: Investigating the Performance of Qwen3.5-35B-A3B (Take 1)
This post contains a broken experiment in which thinking was inadvertently enabled but did not use sampling parameters intended for thinking. See here for a corrected version.
In Part 1 and Part 2, I reported some peculiar behavior for quantized Qwen3.5-2B models:
- KL divergence did not reliably predict downstream coding-agent performance.
- Some quantizations outperformed the original model, while others underperformed.
This post shares early results for a larger variant: Qwen3.5-35B-A3B.
Key Takeaways
vllmcurrently leads this sweep at 46.0% resolved.- Q8_0 and Q5_K_M both outperform the GGUF BF16 variant in resolved rate.
- BF16 and
vllmshow many more timeouts than the quantized GGUF variants. - Public benchmark numbers for this model are meaningfully higher than what I observe locally.
Sweep Summary
| Run | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 181/500 | 36.2% | 6.62 | — | 2103m 41s | Timeout(275), ExitCode(17), Reward(3), Verifier(1) |
| Q5_K_M | 194/500 | 38.8% | 6.62 | 0.0083 | 531m 46s | Timeout(8), ExitCode(23), Reward(3), Verifier(1) |
| Q8_0 | 202/500 | 40.4% | 6.61 | 0.0068 | 575m 45s | Timeout(11), ExitCode(24), Reward(1), Verifier(1) |
| vllm | 230/500 | 46.0% | — | — | 1634m 13s | Timeout(145), ExitCode(22), Reward(6) |
Observations
Timeout behavior is a major differentiator
BF16 and vllm both have substantial timeout counts. At this point, it is unclear whether these are true long-horizon failures or loop-like behaviors similar to what I saw with weaker Qwen3.5-2B quantizations. Either way, timeout behavior appears to be a key driver of aggregate score differences.
Behavior differs from Qwen3.5-2B
With Qwen3.5-2B, the smaller GGUF quantizations (Q5_K_M, Q8_0) outperformed both GGUF BF16 and the vllm model. Qwen3.5-35B-A3B shows a similar pattern, but the vllm model outperforms all the GGUF variants.
GGUF BF16 vs original checkpoint is still surprising
There is a notable gap between GGUF BF16 results and the original model results. That is surprising because the original checkpoint is mostly BF16 with a small number of F32 tensors. I checked the GGUF contents and confirmed F32 tensors are present:
vscode ➜ /workspaces/auto-bench (main) $ gguf-dump /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf | grep "F32" | head -20
INFO:gguf-dump:* Loading: /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf
142: 2048 | 2048, 1, 1, 1 | F32 | blk.0.attn_norm.weight
143: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_a
144: 32768 | 4, 8192, 1, 1 | F32 | blk.0.ssm_conv1d.weight
145: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_dt.bias
148: 128 | 128, 1, 1, 1 | F32 | blk.0.ssm_norm.weight
149: 524288 | 2048, 256, 1, 1 | F32 | blk.0.ffn_gate_inp.weight
153: 2048 | 2048, 1, 1, 1 | F32 | blk.0.ffn_gate_inp_shexp.weight
154: 2048 | 2048, 1, 1, 1 | F32 | blk.0.post_attention_norm.weight
155: 2048 | 2048, 1, 1, 1 | F32 | blk.1.attn_norm.weight
156: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_a
157: 32768 | 4, 8192, 1, 1 | F32 | blk.1.ssm_conv1d.weight
158: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_dt.bias
161: 128 | 128, 1, 1, 1 | F32 | blk.1.ssm_norm.weight
162: 524288 | 2048, 256, 1, 1 | F32 | blk.1.ffn_gate_inp.weight
166: 2048 | 2048, 1, 1, 1 | F32 | blk.1.ffn_gate_inp_shexp.weight
167: 2048 | 2048, 1, 1, 1 | F32 | blk.1.post_attention_norm.weight
168: 2048 | 2048, 1, 1, 1 | F32 | blk.10.attn_norm.weight
169: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_a
170: 32768 | 4, 8192, 1, 1 | F32 | blk.10.ssm_conv1d.weight
171: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_dt.biasIn fact, some tensors appear upcast to F32 in the GGUF file, so raw dtype alone does not explain the performance gap.
Vendor-reported benchmark numbers are much higher
According to Qwen's benchmark page, Qwen3.5-35B-A3B achieves 69.2% on SWE-bench Verified. That is substantially higher than the 46.0% best result in this sweep.
Interestingly, on the Qwen3-Coder-Flash model page, Qwen reports 51.6% on SWE-bench Verified using OpenHands, the same agent framework I am using.
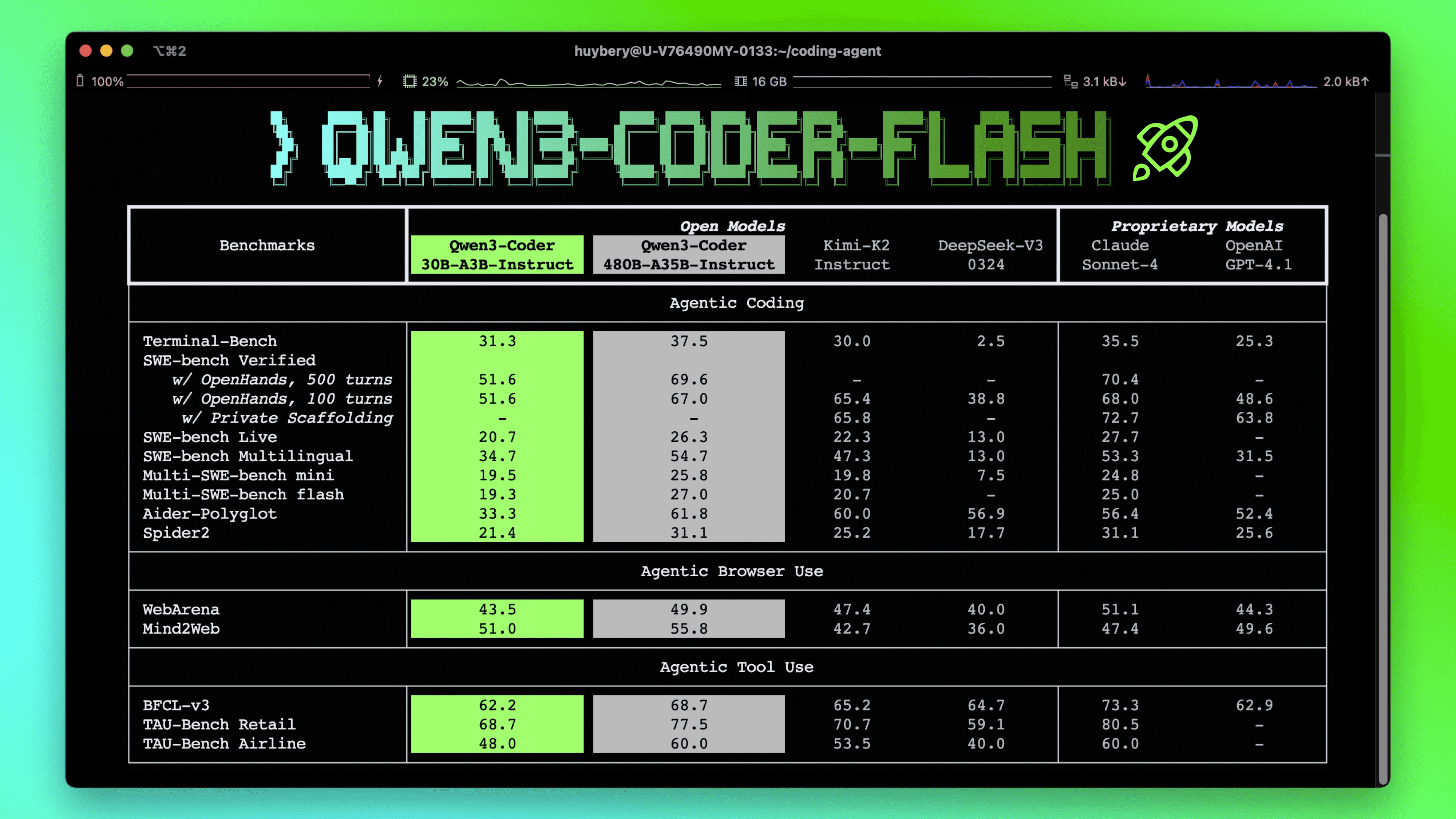
There is also active community discussion about reproducibility for these numbers here. I have not yet found detailed methodology documentation for Qwen3.5's SWE-bench Verified evaluation setup, which may explain part of the discrepancy.
Next Steps
I think the critical question right now is whether the timeouts are legitimate. After reviewing the logs, I think that they may not be. So I'm going to re-run with fewer agents in parallel.

Powered with by Gatsby 5.0