
Benchmarking Quantized LLMs for Local Coding Agents Part 3: Investigating the Performance of Qwen3.5-35B-A3B (Take 2)
In Part 1 and Part 2, I reported some peculiar behavior for quantized Qwen3.5-2B models. In Part 3 Take 1, I reported early results for a larger variant: Qwen3.5-35B-A3B. But I recently discovered that this experiment had a problem that may have been contributing to Timeouts.
The Issue
Qwen3.5 can be used in either "thinking" or "non-thinking" mode. Small models like Qwen3.5-2B default to non-thinking mode, but larger models like Qwen3.5-35B default to thinking mode. When I switched to testing Qwen3.5-35B-A3B, I did not realize that the default mode had changed. That's the first problem; we were testing Qwen3.5-2B without thinking against Qwen3.5-35B-A3B with thinking. The second problem is that Qwen recommends different sampling parameters for thinking vs. non-thinking mode. So we were using a non-thinking sampling configuration with a thinking model. This is likely to have contributed to the Timeouts we observed in Take 1. Manual analysis revealed that many of these cases were indeed thinking loops, which is consistent with the fact that we were using an invalid sampling configuration with a thinking model.
So, mea culpa. Fortunately, I noticed this problem because I wondered why vllm had so many Timeouts and investigated further. I think this is a good example of why we need to conduct and automate these experiments. It's easy to make mistakes when running these experiments manually, and automation can help catch these issues, or at least make sure we don't repeat them once we noticed the problem. And even if you aren't running experiments, it's easy to accidentally use a model with unsupported parameters and get poor results. So it's important to understand the model and make sure you are running with all of the correct parameters.
Take Two
So let's try this again but explicitly set the model to thinking mode and use the recommended sampling parameters for thinking. Recall that we were attempting to see whether the trends we observed for Qwen3.5-2B would hold for Qwen3.5-35B-A3B:
- KL divergence did not reliably predict downstream coding-agent performance.
- Some quantizations outperformed the original model, while others underperformed.
Old, Invalid Results
Here was the old, invalid run summary from Take 1:
| Run | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 181/500 | 36.2% | 6.62 | — | 2103m 41s | Timeout(275), ExitCode(17), Reward(3), Verifier(1) |
| Q5_K_M | 194/500 | 38.8% | 6.62 | 0.0083 | 531m 46s | Timeout(8), ExitCode(23), Reward(3), Verifier(1) |
| Q8_0 | 202/500 | 40.4% | 6.61 | 0.0068 | 575m 45s | Timeout(11), ExitCode(24), Reward(1), Verifier(1) |
| vllm | 230/500 | 46.0% | — | — | 1634m 13s | Timeout(145), ExitCode(22), Reward(6) |
And here were the key takeaways from Take 1:
vllmcurrently leads this sweep at 46.0% resolved.- Q8_0 and Q5_K_M both outperform the GGUF BF16 variant in resolved rate.
- BF16 and
vllmshow many more timeouts than the quantized GGUF variants. - Public benchmark numbers for this model are meaningfully higher than what I observe locally.
New, Corrected Results
Let's look at the corrected (hopefully) results from Take 2. Here is the new run summary:
| Run | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 174/500 | 34.8% | 6.62 | — | 1451m 33s | AddTestsDirError(1), Timeout(24), ExitCode(20), Reward(2) |
| Q5_K_M | 187/500 | 37.4% | 6.62 | 0.0083 | 978m 48s | Timeout(11), ExitCode(19), Reward(1), Verifier(1) |
| Q8_0 | 181/500 | 36.2% | 6.61 | 0.0068 | 989m 28s | Timeout(7), ExitCode(24), Reward(1) |
| vllm | 249/500 | 49.8% | — | — | 1605m 47s | Timeout(42), ExitCode(19), Reward(5), Verifier(2) |
New takeaways:
vllmstill leads this sweep at 49.8% resolved.- Q5_K_M and Q8_0 still outperform the GGUF BF16 variant in resolved rate.
- BF16 and
vllmstill show more timeouts than the quantized GGUF variants, but the gap is much smaller than in Take 1. Manual analysis showed that the models were still making progress rather than being stuck in loops. - Public benchmark numbers for this model are meaningfully higher than what I observe locally.
If you look closely, the takeaways are essentially the same. Oddly enough,
vllm improved its performance with the correct configuration, while the GGUF
variants all performed worse.
Observations
Behavior differs from Qwen3.5-2B
With Qwen3.5-2B, the smaller GGUF quantizations (Q5_K_M, Q8_0) outperformed both GGUF BF16 and the vllm model. Qwen3.5-35B-A3B shows a similar pattern, but the vllm model outperforms all the GGUF variants.
GGUF BF16 vs original checkpoint is still surprising
There is a notable gap between GGUF BF16 results and the original model results. That is surprising because the original checkpoint is mostly BF16 with a small number of F32 tensors. I checked the GGUF contents and confirmed F32 tensors are present:
vscode ➜ /workspaces/auto-bench (main) $ gguf-dump /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf | grep "F32" | head -20
INFO:gguf-dump:* Loading: /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf
142: 2048 | 2048, 1, 1, 1 | F32 | blk.0.attn_norm.weight
143: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_a
144: 32768 | 4, 8192, 1, 1 | F32 | blk.0.ssm_conv1d.weight
145: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_dt.bias
148: 128 | 128, 1, 1, 1 | F32 | blk.0.ssm_norm.weight
149: 524288 | 2048, 256, 1, 1 | F32 | blk.0.ffn_gate_inp.weight
153: 2048 | 2048, 1, 1, 1 | F32 | blk.0.ffn_gate_inp_shexp.weight
154: 2048 | 2048, 1, 1, 1 | F32 | blk.0.post_attention_norm.weight
155: 2048 | 2048, 1, 1, 1 | F32 | blk.1.attn_norm.weight
156: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_a
157: 32768 | 4, 8192, 1, 1 | F32 | blk.1.ssm_conv1d.weight
158: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_dt.bias
161: 128 | 128, 1, 1, 1 | F32 | blk.1.ssm_norm.weight
162: 524288 | 2048, 256, 1, 1 | F32 | blk.1.ffn_gate_inp.weight
166: 2048 | 2048, 1, 1, 1 | F32 | blk.1.ffn_gate_inp_shexp.weight
167: 2048 | 2048, 1, 1, 1 | F32 | blk.1.post_attention_norm.weight
168: 2048 | 2048, 1, 1, 1 | F32 | blk.10.attn_norm.weight
169: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_a
170: 32768 | 4, 8192, 1, 1 | F32 | blk.10.ssm_conv1d.weight
171: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_dt.biasIn fact, some tensors appear upcast to F32 in the GGUF file, so raw dtype alone does not explain the performance gap.
Vendor-reported benchmark numbers are much higher
According to Qwen's benchmark page, Qwen3.5-35B-A3B achieves 69.2% on SWE-bench Verified. That is substantially higher than the 49.8% best result in this sweep.
Interestingly, on the Qwen3-Coder-Flash model page, Qwen reports 51.6% on SWE-bench Verified using OpenHands, the same agent framework I am using.
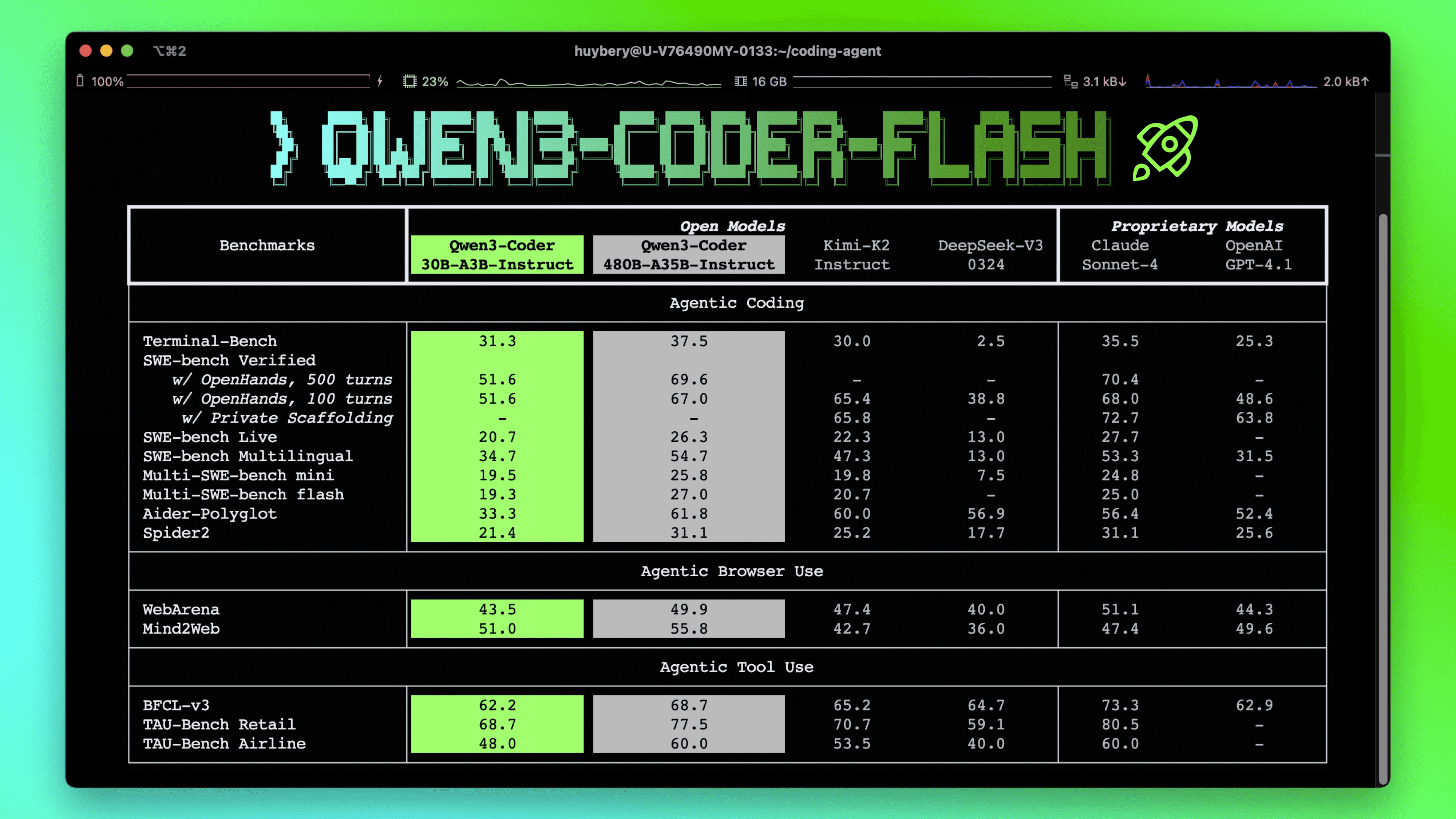
There is also active community discussion about reproducibility for these numbers here. I have not yet found detailed methodology documentation for Qwen3.5's SWE-bench Verified evaluation setup, which may explain part of the discrepancy.
Next Steps / Questions
- Run Qwen3.5-35B-A3B in non-thinking mode.
- Test other Qwen3.5 models.
- Test non-Qwen models.
- Why does BF16 perform worse than the original checkpoint?
- Switch from time-based timeouts (the default in Harbor) to iteration-based limits.

Powered with by Gatsby 5.0