
In Part 1 and Part 2, I reported some peculiar behavior for quantized Qwen3.5-2B models. In Part 3 Take 1, I reported early results for a larger variant: Qwen3.5-35B-A3B. But I recently discovered that this experiment had a problem that may have been contributing to Timeouts.
The Issue
Qwen3.5 can be used in either "thinking" or "non-thinking" mode. Small models like Qwen3.5-2B default to non-thinking mode, but larger models like Qwen3.5-35B default to thinking mode. When I switched to testing Qwen3.5-35B-A3B, I did not realize that the default mode had changed. That's the first problem; we were testing Qwen3.5-2B without thinking against Qwen3.5-35B-A3B with thinking. The second problem is that Qwen recommends different sampling parameters for thinking vs. non-thinking mode. So we were using a non-thinking sampling configuration with a thinking model. This is likely to have contributed to the Timeouts we observed in Take 1. Manual analysis revealed that many of these cases were indeed thinking loops, which is consistent with the fact that we were using an invalid sampling configuration with a thinking model.
So, mea culpa. Fortunately, I noticed this problem because I wondered why vllm had so many Timeouts and investigated further. I think this is a good example of why we need to conduct and automate these experiments. It's easy to make mistakes when running these experiments manually, and automation can help catch these issues, or at least make sure we don't repeat them once we noticed the problem. And even if you aren't running experiments, it's easy to accidentally use a model with unsupported parameters and get poor results. So it's important to understand the model and make sure you are running with all of the correct parameters.
Take Two
So let's try this again but explicitly set the model to thinking mode and use the recommended sampling parameters for thinking. Recall that we were attempting to see whether the trends we observed for Qwen3.5-2B would hold for Qwen3.5-35B-A3B:
- KL divergence did not reliably predict downstream coding-agent performance.
- Some quantizations outperformed the original model, while others underperformed.
Old, Invalid Results
Here was the old, invalid run summary from Take 1:
| Run | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 181/500 | 36.2% | 6.62 | — | 2103m 41s | Timeout(275), ExitCode(17), Reward(3), Verifier(1) |
| Q5_K_M | 194/500 | 38.8% | 6.62 | 0.0083 | 531m 46s | Timeout(8), ExitCode(23), Reward(3), Verifier(1) |
| Q8_0 | 202/500 | 40.4% | 6.61 | 0.0068 | 575m 45s | Timeout(11), ExitCode(24), Reward(1), Verifier(1) |
| vllm | 230/500 | 46.0% | — | — | 1634m 13s | Timeout(145), ExitCode(22), Reward(6) |
And here were the key takeaways from Take 1:
vllmcurrently leads this sweep at 46.0% resolved.- Q8_0 and Q5_K_M both outperform the GGUF BF16 variant in resolved rate.
- BF16 and
vllmshow many more timeouts than the quantized GGUF variants. - Public benchmark numbers for this model are meaningfully higher than what I observe locally.
New, Corrected Results
Let's look at the corrected (hopefully) results from Take 2. Here is the new run summary:
| Run | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 174/500 | 34.8% | 6.62 | — | 1451m 33s | AddTestsDirError(1), Timeout(24), ExitCode(20), Reward(2) |
| Q5_K_M | 187/500 | 37.4% | 6.62 | 0.0083 | 978m 48s | Timeout(11), ExitCode(19), Reward(1), Verifier(1) |
| Q8_0 | 181/500 | 36.2% | 6.61 | 0.0068 | 989m 28s | Timeout(7), ExitCode(24), Reward(1) |
| vllm | 249/500 | 49.8% | — | — | 1605m 47s | Timeout(42), ExitCode(19), Reward(5), Verifier(2) |
New takeaways:
vllmstill leads this sweep at 49.8% resolved.- Q5_K_M and Q8_0 still outperform the GGUF BF16 variant in resolved rate.
- BF16 and
vllmstill show more timeouts than the quantized GGUF variants, but the gap is much smaller than in Take 1. Manual analysis showed that the models were still making progress rather than being stuck in loops. - Public benchmark numbers for this model are meaningfully higher than what I observe locally.
If you look closely, the takeaways are essentially the same. Oddly enough,
vllm improved its performance with the correct configuration, while the GGUF
variants all performed worse.
Observations
Behavior differs from Qwen3.5-2B
With Qwen3.5-2B, the smaller GGUF quantizations (Q5_K_M, Q8_0) outperformed both GGUF BF16 and the vllm model. Qwen3.5-35B-A3B shows a similar pattern, but the vllm model outperforms all the GGUF variants.
GGUF BF16 vs original checkpoint is still surprising
There is a notable gap between GGUF BF16 results and the original model results. That is surprising because the original checkpoint is mostly BF16 with a small number of F32 tensors. I checked the GGUF contents and confirmed F32 tensors are present:
vscode ➜ /workspaces/auto-bench (main) $ gguf-dump /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf | grep "F32" | head -20
INFO:gguf-dump:* Loading: /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf
142: 2048 | 2048, 1, 1, 1 | F32 | blk.0.attn_norm.weight
143: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_a
144: 32768 | 4, 8192, 1, 1 | F32 | blk.0.ssm_conv1d.weight
145: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_dt.bias
148: 128 | 128, 1, 1, 1 | F32 | blk.0.ssm_norm.weight
149: 524288 | 2048, 256, 1, 1 | F32 | blk.0.ffn_gate_inp.weight
153: 2048 | 2048, 1, 1, 1 | F32 | blk.0.ffn_gate_inp_shexp.weight
154: 2048 | 2048, 1, 1, 1 | F32 | blk.0.post_attention_norm.weight
155: 2048 | 2048, 1, 1, 1 | F32 | blk.1.attn_norm.weight
156: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_a
157: 32768 | 4, 8192, 1, 1 | F32 | blk.1.ssm_conv1d.weight
158: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_dt.bias
161: 128 | 128, 1, 1, 1 | F32 | blk.1.ssm_norm.weight
162: 524288 | 2048, 256, 1, 1 | F32 | blk.1.ffn_gate_inp.weight
166: 2048 | 2048, 1, 1, 1 | F32 | blk.1.ffn_gate_inp_shexp.weight
167: 2048 | 2048, 1, 1, 1 | F32 | blk.1.post_attention_norm.weight
168: 2048 | 2048, 1, 1, 1 | F32 | blk.10.attn_norm.weight
169: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_a
170: 32768 | 4, 8192, 1, 1 | F32 | blk.10.ssm_conv1d.weight
171: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_dt.biasIn fact, some tensors appear upcast to F32 in the GGUF file, so raw dtype alone does not explain the performance gap.
Vendor-reported benchmark numbers are much higher
According to Qwen's benchmark page, Qwen3.5-35B-A3B achieves 69.2% on SWE-bench Verified. That is substantially higher than the 49.8% best result in this sweep.
Interestingly, on the Qwen3-Coder-Flash model page, Qwen reports 51.6% on SWE-bench Verified using OpenHands, the same agent framework I am using.
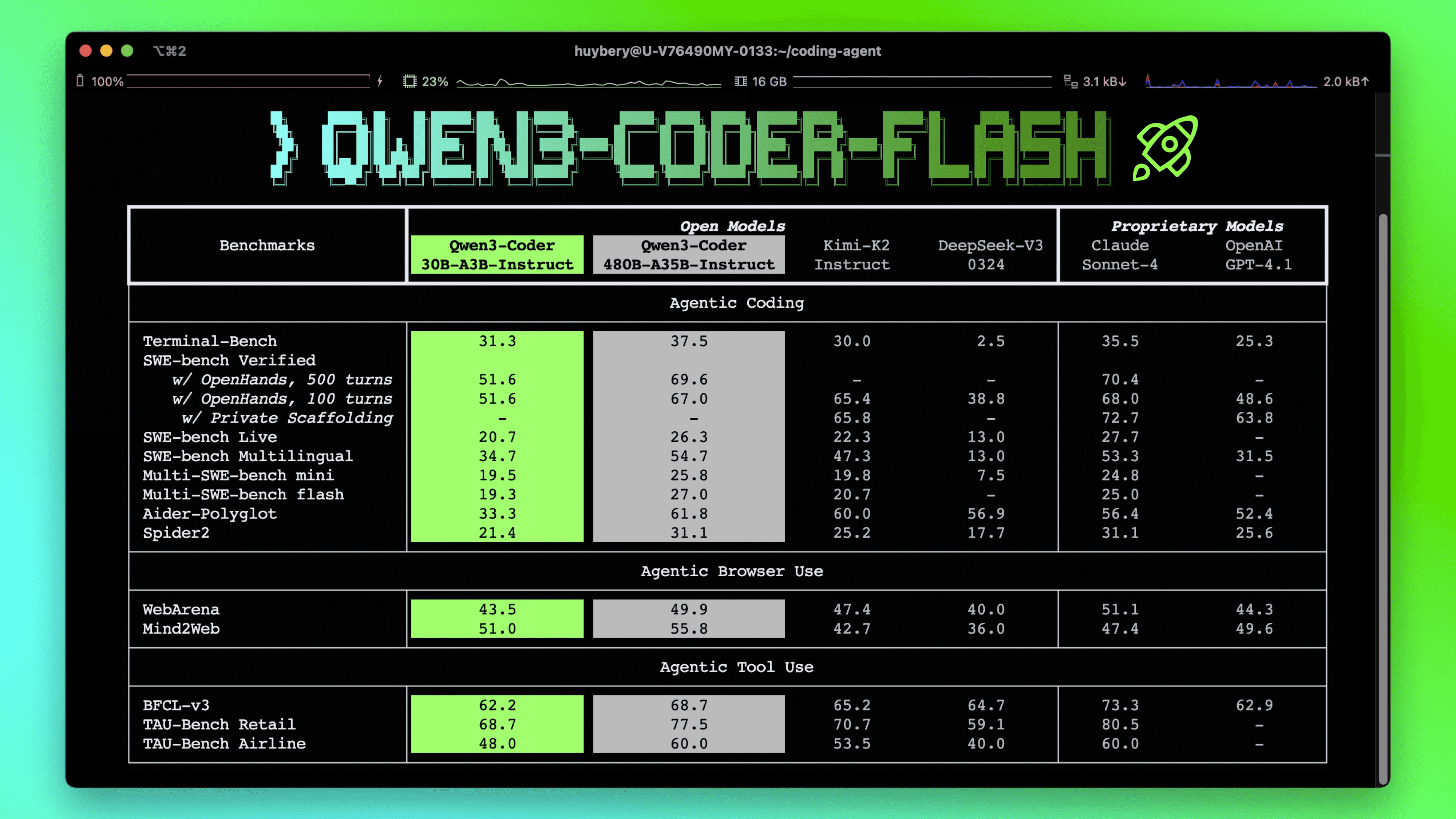
There is also active community discussion about reproducibility for these numbers here. I have not yet found detailed methodology documentation for Qwen3.5's SWE-bench Verified evaluation setup, which may explain part of the discrepancy.
Next Steps / Questions
- Run Qwen3.5-35B-A3B in non-thinking mode.
- Test other Qwen3.5 models.
- Test non-Qwen models.
- Why does BF16 perform worse than the original checkpoint?
- Switch from time-based timeouts (the default in Harbor) to iteration-based limits.
This post contains a broken experiment in which thinking was inadvertently enabled but did not use sampling parameters intended for thinking. See here for a corrected version.
In Part 1 and Part 2, I reported some peculiar behavior for quantized Qwen3.5-2B models:
- KL divergence did not reliably predict downstream coding-agent performance.
- Some quantizations outperformed the original model, while others underperformed.
This post shares early results for a larger variant: Qwen3.5-35B-A3B.
Key Takeaways
vllmcurrently leads this sweep at 46.0% resolved.- Q8_0 and Q5_K_M both outperform the GGUF BF16 variant in resolved rate.
- BF16 and
vllmshow many more timeouts than the quantized GGUF variants. - Public benchmark numbers for this model are meaningfully higher than what I observe locally.
Sweep Summary
| Run | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 181/500 | 36.2% | 6.62 | — | 2103m 41s | Timeout(275), ExitCode(17), Reward(3), Verifier(1) |
| Q5_K_M | 194/500 | 38.8% | 6.62 | 0.0083 | 531m 46s | Timeout(8), ExitCode(23), Reward(3), Verifier(1) |
| Q8_0 | 202/500 | 40.4% | 6.61 | 0.0068 | 575m 45s | Timeout(11), ExitCode(24), Reward(1), Verifier(1) |
| vllm | 230/500 | 46.0% | — | — | 1634m 13s | Timeout(145), ExitCode(22), Reward(6) |
Observations
Timeout behavior is a major differentiator
BF16 and vllm both have substantial timeout counts. At this point, it is unclear whether these are true long-horizon failures or loop-like behaviors similar to what I saw with weaker Qwen3.5-2B quantizations. Either way, timeout behavior appears to be a key driver of aggregate score differences.
Behavior differs from Qwen3.5-2B
With Qwen3.5-2B, the smaller GGUF quantizations (Q5_K_M, Q8_0) outperformed both GGUF BF16 and the vllm model. Qwen3.5-35B-A3B shows a similar pattern, but the vllm model outperforms all the GGUF variants.
GGUF BF16 vs original checkpoint is still surprising
There is a notable gap between GGUF BF16 results and the original model results. That is surprising because the original checkpoint is mostly BF16 with a small number of F32 tensors. I checked the GGUF contents and confirmed F32 tensors are present:
vscode ➜ /workspaces/auto-bench (main) $ gguf-dump /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf | grep "F32" | head -20
INFO:gguf-dump:* Loading: /home/vscode/.cache/huggingface/hub/models--unsloth--Qwen3.5-35B-A3B-GGUF/snapshots/bc014a17be43adabd7066b7a86075ff935c6a4e2/BF16/Qwen3.5-35B-A3B-BF16-00002-of-00002.gguf
142: 2048 | 2048, 1, 1, 1 | F32 | blk.0.attn_norm.weight
143: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_a
144: 32768 | 4, 8192, 1, 1 | F32 | blk.0.ssm_conv1d.weight
145: 32 | 32, 1, 1, 1 | F32 | blk.0.ssm_dt.bias
148: 128 | 128, 1, 1, 1 | F32 | blk.0.ssm_norm.weight
149: 524288 | 2048, 256, 1, 1 | F32 | blk.0.ffn_gate_inp.weight
153: 2048 | 2048, 1, 1, 1 | F32 | blk.0.ffn_gate_inp_shexp.weight
154: 2048 | 2048, 1, 1, 1 | F32 | blk.0.post_attention_norm.weight
155: 2048 | 2048, 1, 1, 1 | F32 | blk.1.attn_norm.weight
156: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_a
157: 32768 | 4, 8192, 1, 1 | F32 | blk.1.ssm_conv1d.weight
158: 32 | 32, 1, 1, 1 | F32 | blk.1.ssm_dt.bias
161: 128 | 128, 1, 1, 1 | F32 | blk.1.ssm_norm.weight
162: 524288 | 2048, 256, 1, 1 | F32 | blk.1.ffn_gate_inp.weight
166: 2048 | 2048, 1, 1, 1 | F32 | blk.1.ffn_gate_inp_shexp.weight
167: 2048 | 2048, 1, 1, 1 | F32 | blk.1.post_attention_norm.weight
168: 2048 | 2048, 1, 1, 1 | F32 | blk.10.attn_norm.weight
169: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_a
170: 32768 | 4, 8192, 1, 1 | F32 | blk.10.ssm_conv1d.weight
171: 32 | 32, 1, 1, 1 | F32 | blk.10.ssm_dt.biasIn fact, some tensors appear upcast to F32 in the GGUF file, so raw dtype alone does not explain the performance gap.
Vendor-reported benchmark numbers are much higher
According to Qwen's benchmark page, Qwen3.5-35B-A3B achieves 69.2% on SWE-bench Verified. That is substantially higher than the 46.0% best result in this sweep.
Interestingly, on the Qwen3-Coder-Flash model page, Qwen reports 51.6% on SWE-bench Verified using OpenHands, the same agent framework I am using.
There is also active community discussion about reproducibility for these numbers here. I have not yet found detailed methodology documentation for Qwen3.5's SWE-bench Verified evaluation setup, which may explain part of the discrepancy.
Next Steps
I think the critical question right now is whether the timeouts are legitimate. After reviewing the logs, I think that they may not be. So I'm going to re-run with fewer agents in parallel.
In Part 1, I introduced auto-bench, a tool for benchmarking quantized LLMs for local coding agents, and shared some results from a preliminary study on a single instance from SWE-bench Verified. The results showed that (1) KL Divergence doesn't predict performance, and (2) quantizations can both outperform and underperform the original model.
In this post, I'll share some new results. Like the other experiment, this one
also focuses on Qwen3.5-2B. Unlike the other experiment, which tested a
single instance of SWE-bench Verified with eight
attempts,
this experiment tests all instances of SWE-bench Verified with one
attempt.
Results
Without further ado, here are the results.
| Quant | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 28/500 | 5.6% | 13.38 | — | 547m 59s | Timeout(47), ExitCode(22), Verifier(2) |
| IQ4_NL | 26/500 | 5.2% | 13.67 | 0.0309 | 423m 21s | Timeout(29), ExitCode(16), Verifier(1) |
| IQ4_XS | 24/500 | 4.8% | 13.68 | 0.0318 | 493m 7s | Timeout(39), ExitCode(15), Reward(1), Verifier(2) |
| Q3_K_M | 30/500 | 6.0% | 14.33 | 0.0774 | 785m 43s | Timeout(67), ExitCode(21) |
| Q3_K_S | 20/500 | 4.0% | 15.08 | 0.1334 | 742m 25s | Timeout(73), ExitCode(25), Reward(1), Verifier(1) |
| Q4_0 | 24/500 | 4.8% | 13.91 | 0.0454 | 407m 34s | Timeout(25), ExitCode(21), Verifier(1) |
| Q4_1 | 36/500 | 7.2% | 13.68 | 0.0273 | 766m 19s | Timeout(59), ExitCode(16), Reward(1), Verifier(1) |
| Q4_K_M | 27/500 | 5.4% | 13.79 | 0.0230 | 357m 0s | Timeout(20), ExitCode(23), Verifier(2) |
| Q4_K_S | 19/500 | 3.8% | 13.78 | 0.0274 | 519m 39s | Timeout(38), ExitCode(23), Reward(1), Verifier(1) |
| Q5_K_M | 62/500 | 12.4% | 13.46 | 0.0082 | 784m 58s | Timeout(61), ExitCode(23), Reward(1), Verifier(1) |
| Q5_K_S | 46/500 | 9.2% | 13.49 | 0.0100 | 563m 27s | Timeout(30), ExitCode(25), Reward(1), Verifier(3) |
| Q6_K | 58/500 | 11.6% | 13.48 | 0.0035 | 820m 37s | Timeout(62), ExitCode(20), Verifier(1) |
| Q8_0 | 37/500 | 7.4% | 13.39 | 0.0012 | 598m 13s | Timeout(46), ExitCode(17), Verifier(1) |
| UD-IQ2_M | 1/500 | 0.2% | 17.61 | 0.2677 | 1866m 13s | Timeout(300), ExitCode(24), Verifier(1) |
| UD-IQ2_XXS | 1/500 | 0.2% | 27.11 | 0.7018 | 2196m 49s | Timeout(371), ExitCode(19) |
| UD-IQ3_XXS | 5/500 | 1.0% | 15.31 | 0.1549 | 1481m 24s | Timeout(230), ExitCode(24), Verifier(1) |
| UD-Q2_K_XL | 2/500 | 0.4% | 17.15 | 0.2388 | 442m 51s | Timeout(29), ExitCode(27) |
| UD-Q3_K_XL | 48/500 | 9.6% | 13.94 | 0.0520 | 738m 44s | Timeout(57), ExitCode(19), Reward(1), Verifier(1) |
| UD-Q4_K_XL | 57/500 | 11.4% | 13.60 | 0.0164 | 759m 13s | Timeout(48), ExitCode(18), Reward(2), Verifier(2) |
| UD-Q5_K_XL | 62/500 | 12.4% | 13.51 | 0.0077 | 932m 37s | Timeout(71), ExitCode(18), Reward(2), Verifier(1) |
| UD-Q6_K_XL | 29/500 | 5.8% | 13.48 | 0.0020 | 539m 38s | Timeout(35), ExitCode(20), Verifier(1) |
| UD-Q8_K_XL | 36/500 | 7.2% | 13.37 | 0.0011 | 502m 1s | Setup(1), Timeout(35), ExitCode(23), Verifier(2) |
| vllm | 26/500 | 5.2% | — | — | 521m 14s | Timeout(49), ExitCode(11), Verifier(1) |
And the plot of % Resolved vs KL Divergence:
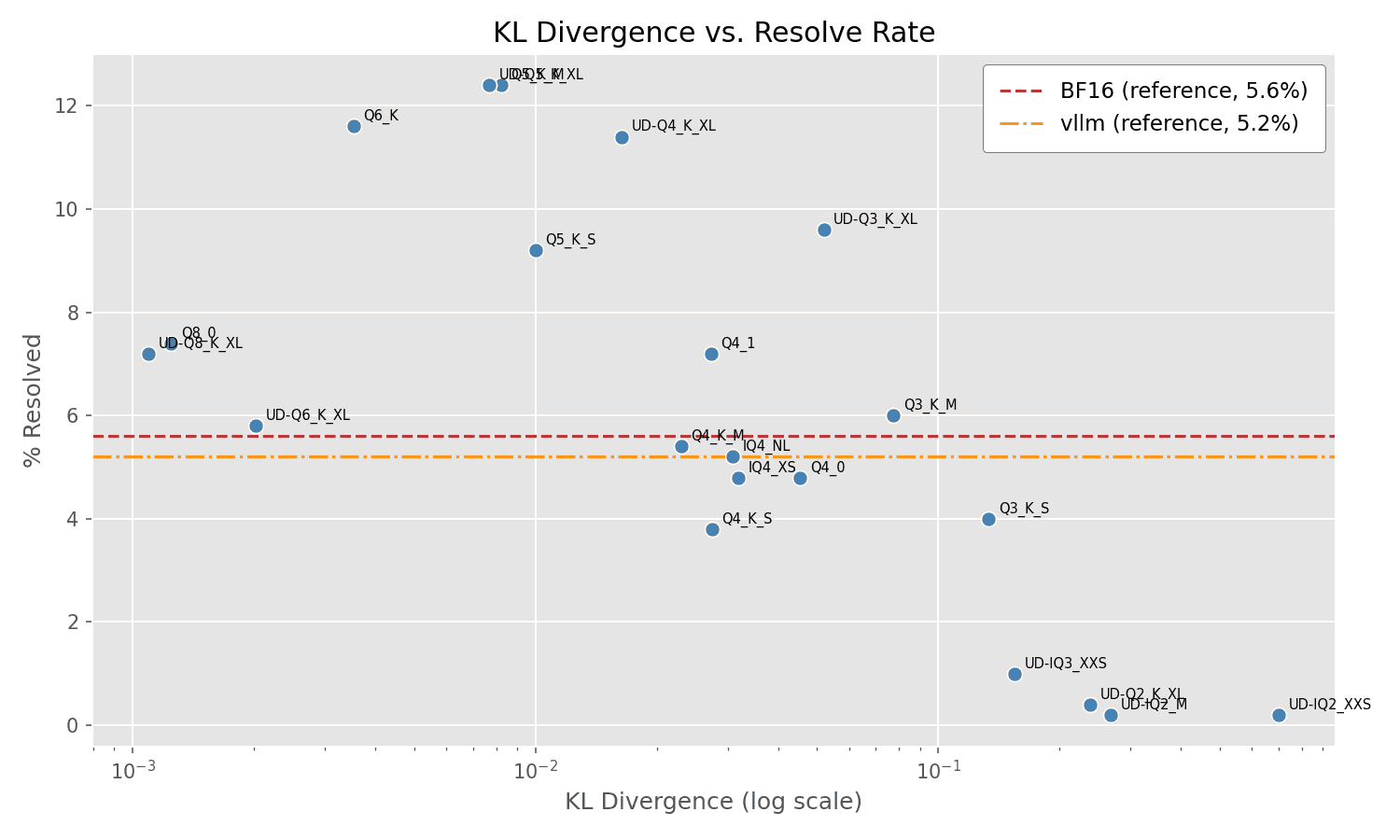
Observations
A few observations:
- The overall resolve rates are low across the board. This is not a very powerful model. I intentionally selected an easy problem instance for the Part 1 experiment.
- As in Part 1, many of the "mid-range" quantizations outperform the original model, yet small and large quantizations underperform. This is consistent with the idea that some quantizations are actually beneficial, while others are harmful.
- Also as in Part 1, KL Divergence does not fully explain performance.
What next?
This experiment largely confirmed the findings from Part 1 about the Qwen3.5-2B model. An open question is whether these results apply to other models as well. I plan to run similar experiments on larger variants of the Qwen3.5 family next, but I won't be evaluating every quantization. Too much time is wasted on bad quantizations because they get stuck in endless loops. Instead, I'll probably try a select few quantizations, such as BF16, Q8_0, and Q5_K_M. Although I am interested in understanding these peculiar behaviors, my primary goal is actually to find which models and quantizations are usable.
OOAnalyzer is one of my favorite projects for a few reasons. The underlying problem is deceptively hard. If you look closely enough, OO executables have a lot of evidence in them. When you consider each piece in isolation, it can seem simple. But when you try to combine all of the evidence, you wind up with a combinatorial explosion of possibilities that is pruned by constraints in very complex ways. I also like it because it's a very practical problem. People actually use OOAnalyzer, despite all of its limitations—a testament to how even flawed solutions to hard problems can be valuable.
OOAnalyzer is a successor to an earlier project that predated me at SEI called ObjDigger. OOAnalyzer's big innovation was to use what we called "hypothetical reasoning" about ambiguous scenarios. In a nutshell, we often faced a choice between several possibilities. For example, class D inherits from class B, and we see class M in class D's vftable. We know that M is either a method of D or a method of B. We can't tell which one it is, but we can make a guess, and see if that leads to a contradiction. If it does, then we know our guess was wrong, and we can eliminate that possibility and try the others. This is a powerful technique that was partially enabled by our use of Prolog in OOAnalyzer, specifically Prolog's backtracking search.
That being said, OOAnalyzer's hypothetical reasoning is not perfect. One problem we encountered while developing OOAnalyzer was that there could be a long gap between a guess and when the contradiction is detected. Let's say we make a guess that eventually will cause a contradiction, but we must make 10 other boolean guesses before detecting the contradiction. At that point, Prolog would backtrack the guesses, starting with the most recent guess. Unfortunately, Prolog has no way of knowing that the actual cause was much further back, and it would waste time re-exploring models that were doomed to fail. Over time, we began to shape the rules in OOAnalyzer to avoid this problem. We ordered the rules so that any guess likely to lead to a contradiction would be detected immediately. This worked, but also limited our reasoning power.
Another problem with OOAnalyzer is how it decides on a final model. The final model is simply the first one that allows all guesses (uncertainties) to be resolved and does not lead to a contradiction. OOAnalyzer's guessing rules are ordered so that the more important ones are made earlier, when they have less chance of conflicting with a previous decision. But there is no guarantee that this model is the best one, or even close to it! Over time, I formed the opinion that OOAnalyzer is really an optimization problem. Our rules permit multiple models that could explain the evidence. But some are better than others. For example, many OO programs without vftables and vbtables can be explained by a model with no OO classes or methods. This is valid, but not very useful for the analyst.
Finally, OOAnalyzer involves a lot of constraints. For example, we might know that a method is either a constructor, real destructor, or deleting destructor. Obviously if we learn that the same method is not a destructor, it must be a constructor. Because we didn't use constraints in OOAnalyzer, we had to implement this type of logic manually. It works, but it's not elegant.
Over time, I've wondered how to better frame the OOAnalyzer problem, and recently I started exploring Answer Set Programming (ASP) as a potential answer. ASP is a form of declarative programming that is based on the stable model semantics of logic programming. It is designed to solve combinatorial search problems, and it has built-in support for constraints and optimization. ASP has several key features:
- It allows for declarative rules, like Prolog.
- It has built-in support for constraints.
1 { constructor(X); real_destructor(X); deleting_destructor(X) } 1means that exactly one of the three predicates must be true for any given X. - It has built-in support for optimization. We can assign weights to different models and ask the solver to find the global optimum, or the best solution found within a time limit.
In my spare time, I've been porting parts of OOAnalyzer to ASP here. I've been pleasantly surprised by how well it has worked so far. The code is much more concise and easier to read than the Prolog version. The constraints are much easier to express. For example, here's a rule that says if we see certain behavior (like installing vftables), we know that the method is a constructor or destructor:
% A method that writes a vftable/vbtable into its own this-pointer must be
% exactly one of: constructor, real destructor, or deleting destructor.
% Covers:
% reasonConstructor (rules.pl:192) — elimination: only remaining candidate
% reasonRealDestructor (rules.pl:388) — elimination: only remaining candidate
% reasonDeletingDestructor (rules.pl:575) — elimination: only remaining candidate
%!trace_rule {"% is exactly one of constructor, real destructor, or deleting destructor", Method}
1 { constructor(Method) ; realDestructor(Method) ; deletingDestructor(Method) } 1 :-
certainConstructorOrDestructor(Method).Similarly, here's a rule saying that a method can only be one of a constructor, real destructor, or deleting destructor:
constructorDestructorKind(Method, constructor) :-
constructor(Method).
constructorDestructorKind(Method, realDestructor) :-
realDestructor(Method).
constructorDestructorKind(Method, deletingDestructor) :-
deletingDestructor(Method).
% Covers:
% insanityConstructorAndRealDestructor (insanity.pl:226)
% insanityConstructorAndDeletingDestructor (insanity.pl:240)
% reasonNOTConstructor_B (rules.pl:281) — realDestructor → notConstructor
% reasonNOTConstructor_C (rules.pl:288) — deletingDestructor → notConstructor
% reasonNOTRealDestructor_B (rules.pl:443) — constructor → notRealDestructor
% reasonNOTRealDestructor_C (rules.pl:448) — deletingDestructor → notRealDestructor
% reasonNOTDeletingDestructor_B (rules.pl:632) — constructor → notDeletingDestructor
% reasonNOTDeletingDestructor_C (rules.pl:637) — realDestructor → notDeletingDestructor
%!trace_rule {"% has multiple constructor/destructor kinds", Method}
insanity(insanityMultipleConstructorDestructorKinds, (Method,Count)) :-
method(Method),
Count = #count { Kind : constructorDestructorKind(Method, Kind) },
Count > 1.As the comment above says, this rule covers about 8 different rules in OOAnalyzer. In ASP, we can express the same thing much more concisely.
OOAnalyzer-ASP can already read OOAnalyzer's facts format. You can see some examples of the results in the repository. Bear in mind that not all rules are ported yet.
One last thing I'll share is automatic explanations of models. I've been using the xclingo2 library to generate explanations for the ASP models. Even as OOAnalyzer's developer, it can be hard to understand how it reasons, because it could involve dozens of related conclusions. This is exacerbated in ASP because constraints and the optimization criteria are "silent". But even so, xclingo2 can generate detailed proof trees showing why a particular atom was included in the model. Here's an example of a proof tree for why a method is a constructor:
|__4266400 is a constructor
| |__4266400 is a method;4266400 is a method because 4266176 calls it at this-offset 0
| | |__thunk 4264566 resolves to 4266400
| | | |__thunk 4266400 resolves to 4266400
| | |__4266176 is a method;4266176 is a method because it is a known constructor
| | | |__4266176 is a constructor;4266176 is exactly one of constructor, real destructor, or deleting destructor
| | | | |__4266176 must be a constructor or destructor because it writes a vftable into its own this-pointer
| | | | | |__4266176 writes confirmed vftable 4290632 at offset 0
| | | | | | |__4290632 is a confirmed vftable;4290632 is a confirmed vftable because RTTI says soSo is this the next generation OOAnalyzer? Theoretically, I think the answer is yes! But practically, it's unclear how well this is going to scale to real programs. One of the downsides to most ASP implementations is that they ground eagerly. Because executables can have a lot of evidence, it's possible this can lead to a combinatorial explosion in the number of ground rules. Because OOAnalyzer's rules involve negation and recursion in complex ways, it's hard to say how much of an issue this will be. We're able to find the optimal model on all of the toy OOAnalyzer programs, but that doesn't mean much. There are alternative approaches to ASP, like lazy grounding, but they are less mature. I'm hopeful that with cautious engineering, we can make this work on real programs, but only time will tell. In the meantime, I'm having fun exploring this new approach to the problem!
Like many people, when I'm on the go and need to do something, I reach for an LLM assistant. In my case, that's Claude. Anthropic, OpenAI, and Google all have a variety of connections to various services. But what happens when they don't have a connection to a service that you want?
For example, I've been dieting, which means I need to track my calories. I use MyFitnessPal for that. Tracking calories is laborious and difficult. Much of the difficulty comes from estimating the calories in a meal. What are the ingredients and components, and how much of each is there? If only there was a way to take a picture and have an intelligent system analyze the image and determine the calories. Oh wait, we do—LLM assistants!
Sadly, as far as I know, there's no connection to MyFitnessPal in any of the major LLM assistants. Wouldn't it be nice if my LLM could automatically log the estimated calories for me after analyzing the image?
This is where self-hosted MCP servers come in. Claude now allows you to add "custom integrations" to your account that it can use on the mobile app or on claude.ai. These custom integrations are just SSE-based MCP servers. If you have a server, you can run these integrations yourself.
There were a few complications for me:
-
There are several MyFitnessPal MCP servers, but they are stdio servers, which do not expose the HTTP endpoints that Claude's custom integrations require.
-
Although I have a server, it is behind a firewall, and I don't want to change that.
Fortunately, these problems aren't that difficult to solve. For the first problem, I used supergateway to expose the stdio MCP server as an SSE MCP server. For the second problem, I used ngrok to create a secure tunnel to my server without changing my firewall settings.
Setting up projects like this has never been easier. I asked Claude Code to
help, and it generated the docker-compose solution in about thirty minutes.
As is becoming more frequent, I found that the existing MyFitnessPal MCP servers were all lacking features I needed, such as the ability to see recent and favorite foods, delete log entries, and so on. So I forked them and vibe-coded the features I wanted. Forking the MCP servers and customizing them took a couple of hours spread over a few days of testing. Coding agents make this type of project easier than ever.
I'm still working out some edge cases with meal recognition and calorie estimation accuracy, but I've been really happy with the core functionality. Here's a screenshot of Claude estimating calories for some fries I photographed and logging them to MyFitnessPal automatically:

In claude.ai, I've created a project and been using memory to teach Claude about my diet, which is fortunately quite repetitive.
Check out the docker-compose setup and MyFitnessPal MCP server fork on GitHub. The MyFitnessPal MCP server is included as a submodule.
New open LLMs are released constantly and keep improving. Gemma 4 was recently claimed to be groundbreaking, but when I tried the quantized version for coding agents like opencode, it was completely unusable—it gets stuck in output loops or unable to call tools with correct syntax. This is the norm, not an exception. Most quantized open LLMs I try for agentic AI simply don't work. Finding a setup that does requires trial and error across model, quantization, and dozens of settings.
I just want a command I can run to get a working LLM for my GPU. No hours of experimentation. No guessing at combinations. Just a proven setup. I couldn't find one, so I built auto-bench.
auto-bench
Auto-bench is a tool that allows you to define experiments, automatically run LLM inference servers with the proper settings, and execute a set of benchmarks against them. Rather than reinventing the wheel, I'm currently using Harbor Framework to run the tests. Auto-bench has first-class support for quantized models. This is important, because most existing benchmarks and leaderboards don't consider quantization, even though that is how many people run models.
My project is in its earliest stages, but I have at least one experiment to share: testing various quantizations of the Qwen3.5-2B model on a single problem instance from SWE-bench Verified (swe-bench/sympy__sympy-22914). I deliberately selected an easy instance to see if quantized models can perform basic tool calls to solve an easy problem.
Here is how this experiment is configured in auto-bench:
# Benchmark 22 quants of Qwen3.5-2B on a single SWE-bench instance
# Usage: auto-bench run configs/qwen-2b-quant-sweep.yaml
name: qwen-2b-quant-sweep
backend_type: llamacpp
dataset: SWE-bench/SWE-bench_Verified
instance_ids:
- swe-bench/sympy__sympy-22914
model:
name: Qwen3.5-2B
source: huggingface
repo_id: unsloth/Qwen3.5-2B-GGUF
sweep:
- label: BF16
filename: Qwen3.5-2B-BF16.gguf
- label: Q3_K_S
filename: Qwen3.5-2B-Q3_K_S.gguf
- label: Q5_K_M
filename: Qwen3.5-2B-Q5_K_M.gguf
- label: Q5_K_S
filename: Qwen3.5-2B-Q5_K_S.gguf
- label: Q6_K
filename: Qwen3.5-2B-Q6_K.gguf
# ... 17 more quantizations
sampling:
temperature: 0.7
top_p: 0.8
top_k: 20
min_p: 0.0
presence_penalty: 1.5
repetition_penalty: 1.0
agent:
agent: openhands
env: docker
attempts: 4
limit: 1
setup_multiplier: 10.0
evaluation:
run_evaluation: truePart of my goal is to include all information needed to actually run the models properly. For example, the sampling section includes the sampling parameters that are recommended by Qwen for best performance, and these types of details can make a huge effect! My vision is to eventually have a leaderboard that will provide you with a llama.cpp command-line to run the model with the proper settings, and then you can just copy and paste that command to get a working LLM for your coding agent.
Results
Before diving into the data, here's what the columns mean:
- Resolved: Number of problem instances successfully resolved by the agent
- Total: Total number of attempts (8 in this case)
- % Resolved: Resolution rate as a percentage
- PPL (Perplexity): Measures the model's confidence in its predictions. Lower is generally better, though surprisingly this doesn't always correlate with task success
- KL: Kullback-Leibler divergence—how much the quantized model's output distribution diverges from the original model's. Lower is better, but as we'll see, it's not a strong predictor of task performance
- Runtime: Total time to run all attempts
- Exceptions: Types of errors encountered (e.g., timeouts, exit code errors)
| Quant | Resolved | % | PPL | KL | Runtime | Exceptions |
|---|---|---|---|---|---|---|
| BF16 | 0/8 | 0% | 13.38 | — | 3m 37s | — |
| IQ4_NL | 1/8 | 12.5% | 13.67 | 0.0309 | 3m 53s | — |
| IQ4_XS | 0/8 | 0% | 13.68 | 0.0318 | 51m 53s | Timeout, ExitCode |
| Q3_K_M | 2/8 | 25% | 14.33 | 0.0774 | 51m 48s | Timeout |
| Q3_K_S | 5/8 | 62.5% | 15.08 | 0.1334 | 51m 39s | Timeout |
| Q4_0 | 4/8 | 50% | 13.91 | 0.0454 | 19m 5s | — |
| Q4_1 | 3/8 | 37.5% | 13.68 | 0.0273 | 11m 14s | — |
| Q4_K_M | 1/8 | 12.5% | 13.79 | 0.0230 | 4m 8s | ExitCode |
| Q4_K_S | 2/8 | 25% | 13.78 | 0.0274 | 4m 43s | — |
| Q5_K_M | 8/8 | 100% | 13.46 | 0.0082 | 51m 48s | Timeout |
| Q5_K_S | 6/8 | 75% | 13.49 | 0.0100 | 8m 53s | — |
| Q6_K | 7/8 | 87.5% | 13.48 | 0.0035 | 51m 54s | Timeout |
| Q8_0 | 4/8 | 50% | 13.39 | 0.0012 | 51m 49s | Timeout |
| UD-IQ2_M | 0/8 | 0% | 17.61 | 0.2677 | 51m 56s | Timeout(5) |
| UD-IQ2_XXS | 0/8 | 0% | 27.11 | 0.7018 | 51m 58s | Timeout(6), ExitCode |
| UD-IQ3_XXS | 0/8 | 0% | 15.31 | 0.1549 | 51m 49s | Timeout |
| UD-Q2_K_XL | 0/8 | 0% | 17.15 | 0.2388 | 51m 49s | Timeout(2) |
| UD-Q3_K_XL | 6/8 | 75% | 13.94 | 0.0520 | 51m 56s | Timeout(2) |
| UD-Q4_K_XL | 6/8 | 75% | 13.60 | 0.0164 | 7m 40s | — |
| UD-Q5_K_XL | 8/8 | 100% | 13.51 | 0.0077 | 18m 2s | — |
| UD-Q6_K_XL | 3/8 | 37.5% | 13.48 | 0.0020 | 6m 51s | — |
| UD-Q8_K_XL | 3/8 | 37.5% | 13.37 | 0.0011 | 5m 49s | — |
| vllm | 1/8 | 12.5% | — | — | 6m 32s | — |
The Base Model Is Broken
The most striking finding is that the unquantized base model (shown as vllm in the results) achieves only 12.5% resolution—worse than most quantized versions. BF16, which is nearly the original model without quantization, also consistently fails at 0%. This suggests the base model is fundamentally broken for this coding task, but quantization somehow fixes it.
Many medium-sized quantizations (Q5_K_M, UD-Q5_K_XL, Q6_K) achieve 100%, 100%, and 87.5% resolution respectively. Yet larger quantizations like Q8_0 fail again at 50%. This isn't about bigger being better—it's about finding the quantization that repairs the base model's broken reasoning.
KL Divergence Doesn't Predict Success
The KL (Kullback-Leibler) divergence column measures how much a quantized model's output distribution diverges from the original. If the base model is broken for this task, then staying close to the original (low divergence) just means inheriting the same brokenness. That could explain why there's no strong correlation between divergence and success.
Q5_K_M achieves 100% resolution with low divergence (0.0082)—but so does UD-Q5_K_XL with similar low divergence. Meanwhile, BF16 (essentially 0 divergence, nearly the original) fails completely at 0%. Some high-divergence models like UD-IQ2_XXS fail too, but others like Q3_K_S achieve 62.5% with divergence of 0.1334.
The plot tells the story: failing models (0 resolved) scatter across the entire divergence range—some very close to the original, some far away. If you stayed loyal to a broken base model, you'd fail. If you accidentally diverged in the right way, you'd succeed. KL divergence alone can't tell you which happened.
Multiple Failure Modes
There are two distinct failure modes visible in the results.
Failure Mode 1: Infinite Loops (AgentTimeoutError)
Many quantizations exhibit infinite looping behavior, where the agent gets stuck generating the same outputs repeatedly and eventually hits the timeout limit. Models like UD-IQ2_M, UD-IQ2_XXS, IQ4_XS, and IQ3_XXS show multiple AgentTimeoutError instances. Interestingly, this failure mode appears to correlate strongly with extremely aggressive quantization (e.g., IQ2 variants with very high KL divergence > 0.26).
Failure Mode 2: Silent Failure
The second failure mode is when the agent runs to completion without timing out, but simply fails to correctly solve the problem. Models like BF16, UD-IQ2_XXS, and UD-IQ3_XXS never produce output loops, but they still achieve 0% resolution. This suggests that the quantization has degraded the model's reasoning ability below a critical threshold where it can't effectively reason about code, even if it's still syntactically generating valid tool calls.
Conclusion: The Base Model Is Broken, Quantization Fixes It
The core finding is that the unquantized base model (12.5% resolution) and near-original BF16 (0% resolution) both fail for this coding task. Yet specific quantizations like Q5_K_M and UD-Q5_K_XL achieve 100%. Quantization isn't degrading a working model—it's repairing a broken one.
Notice in the visualization: models that fail (0 resolved) scatter across the entire KL divergence range, from very close to the original all the way to extremely divergent. Models that succeed tend to cluster at low divergence. But the scatter on the left side proves you can't predict failure from divergence—some quantizations stay very close to the original yet still fail.
The lesson is that model quality for coding agents is challenging to predict. This is why auto-bench exists—to empirically measure what actually works for your specific use case.
Open Questions and Limitations
This experiment demonstrates an interesting phenomenon, but it's based on a single problem instance from a single model family. The findings should be interpreted with appropriate caution:
- Generalization to other models: Do these patterns hold for Llama, Mistral, or other model families? The behaviors might be Qwen-specific.
- Generalization to other instances: I deliberately chose an easy instance to see if quantized models could work at all. Would the patterns hold on harder instances? SWE-bench Verified spans easy to extremely difficult problems.
- Generalization to other tasks: Would we see similar results on SWE-bench instances beyond Verified, or on other benchmarks like HumanEval or MBPP?
- Sampling parameter sensitivity: How much of the improvement from quantized models comes from properly-tuned sampling parameters? A controlled ablation would be valuable.
I'm actively running experiments to answer these questions! The auto-bench framework is designed to scale to hundreds of model/quantization combinations and thousands of problem instances. Stay tuned for results on larger model families, more problem instances, and more task types.
I'm happy to announce that my student Luke Dramko's paper "Idioms: A Simple and Effective Framework for Turbo-Charging Local Neural Decompilation with Well-Defined Types" has been accepted to NDSS 2026! Put simply, the paper shows that neural decompilers benefit greatly from explicitly predicting and recovering user-defined types (structs, unions, etc.) referenced in decompiled code.
Paper & Code
- Paper: https://edmcman.github.io/papers/ndss26.pdf
- Code & models: https://github.com/squareslab/idioms
The paper has a great motivating example that I'll borrow here. The example starts with a C function that uses a struct type:
struct hash {
int hash_size;
int item_cnt;
struct gap_array *data;
int (*hash_make_key)(void *item);
int (*cmp_item)(void *item1, void *item2);
};
struct gap_array {
int len;
void **array;
};
int hash_find_index(struct hash *h, void *item) {
void *cnx;
int index = hash_make_key(h, item);
int cnt = 0;
cnx = gap_get(h->data, index);
while (cnx != NULL) {
if (cnt++ > h->hash_size) return -1;
if (!h->cmp_item(cnx, item)) break;
index = hash_next_index(h, index);
cnx = gap_get(h->data, index);
}
if (cnx == NULL) return -1;
return index;
}If you've read this blog, it will probably not surprise you that even state-of-the-art decompilers like Hex-Rays struggle to recover this code in a human-readable form. Here is the output from Hex-Rays:
__int64 __fastcall func4(__int64 a1, __int64 a2) {
int v2; // eax
__int64 result; // rax
int v4; // [rsp+10h] [rbp-10h]
unsigned int v5; // [rsp+14h] [rbp-Ch]
__int64 i; // [rsp+18h] [rbp-8h]
v5 = func2(a1, a2);
v4 = 0;
for (i = func1(*(_QWORD *)(a1 + 8), v5); i;
i = func1(*(_QWORD *)(a1 + 8), v5)) {
v2 = v4++;
if (v2 > *(_DWORD *)a1) return 0xFFFFFFFFLL;
if (!(*(unsigned int(__fastcall **)(__int64, __int64))(a1 + 24))(i, a2))
break;
v5 = func3((_DWORD *)a1, v5);
}
if (i)
result = v5;
else
result = 0xFFFFFFFFLL;
return result;
}There are a lot of problems with this output, but the most serious is that the
information about the hash struct has been completely lost.
A very exciting line of decompilation research is neural decompilation, which leverages neural models to either (1) directly decompile code, or (2) improve the decompiled code from traditional (non-neural) decompilers. I am personally extremely excited about the latter approach, which uses neural models to post-process the output of traditional decompilers such as Hex-Rays. Traditional decompilers have been studied for decades, so why not leverage their strengths while using neural models to fix their weaknesses? One popular example is the LLM4Decompile models. Here is an example of LLM4Decompile's output for this function:
int FUN_00100155(struct FUN_0009ff84 *VAR_0,void *VAR_1){
int VAR_2;
int VAR_3;
void *VAR_4;
VAR_2 = FUN_0009ff86(VAR_0, VAR_1);
VAR_3 = 0;
VAR_4 = FUN_0009ff88(VAR_0->VAR_5, VAR_2);
while (VAR_4) {
if (VAR_0->VAR_6 < VAR_3) { return -1; }
if (!VAR_0->VAR_7(VAR_4, VAR_1)) { break; }
VAR_2 = FUN_0009ff89(VAR_0, VAR_2);
VAR_4 = FUN_0009ff88(VAR_0->VAR_5, VAR_2);
VAR_3++;
}
if (VAR_4) { return VAR_2; }
return -1;
}Unlike Hex-Rays, LLM4Decompile correctly identifies that the function's
arguments are pointers and that the first argument is a pointer to a struct. But
what is struct FUN_0009ff84 and what are its fields, VAR_5, VAR_6, and
VAR_7? And perhaps most importantly for reverse engineers, what offsets are
those fields at? This information is crucial for understanding the code, but
it has been omitted by the model.
One of Idioms' main contributions is to modify the training process of neural models so that they produce well-defined types such as structs with named fields. Unsurprisingly, this makes decompiled code much easier to understand. Here is the output of Idioms on this function:
struct hash_t {
int size;
int count;
struct hash_table_t *table;
int (*hash)(void *key);
int (*cmp)(void *key1, void *key2);
};
struct hash_table_t {
int size;
void **items;
};
int hash_find(struct hash_t *hash, void *key) {
int index = hash_index(hash, key);
int i = 0;
void *item = hash_get(hash->table, index);
while (item != ((void *)0)) {
if (i++ > hash->size) { return -1; }
if (hash->cmp(item, key) == 0) { break; }
index = hash_next(hash, index);
item = hash_get(hash->table, index);
}
return (item == ((void *)0)) ? -1 : index;
}An Unexpected Advantage of Joint Predictions
Perhaps surprisingly, in addition to improving the readability of the code, jointly predicting both code and types also significantly improves the accuracy of the decompiled code!
Across multiple models and evaluation metrics, Idioms consistently outperforms prior neural decompilers:
- On ExeBench: Idioms achieves 54.4% test-pass accuracy (vs. 46.3% for LLM4Decompile and 37.5% for Nova).
- On RealType: A dataset we introduce that contains substantially more and more realistic user-defined types (UDTs); Idioms improves correctness metrics by 95–205% over prior work.
- Context helps: Adding neighboring-function context improves UDT recovery—up to 63% improvement in structural accuracy—with little downside for larger models.
Beyond Decompilation
Surprisingly (to me), Idioms also outperforms standalone type recovery tools such as Retypd, BinSub, TRex, and TypeForge, by at least 73%. This suggests that generative, context-aware approaches may be well suited to resolving the inherent ambiguity of type recovery than prior approaches, even though this was not the original motivation of Idioms.
(Apologies in advance, this is probably going to be rambling.)
I spend a lot of time looking at various research artifacts. Yesterday, I was looking at several verification artifacts, and I was struck by how much impact small details like a Docker container can have. One of the projects I was using is STOKE. STOKE is a cool project, but the salient detail for this post is that it is an abandoned research project. The last commit was in December 2020. This is very common: Ph.D. student creates a project, maintains project, graduates, and then no longer maintains project. Despite that, STOKE has a Docker container, which makes using the project trivial.
In contrast, I was also attempting to run Psyche-C this week. Like STOKE, there's a fair bit of bitrot on the branch that contains the type-inference component. Unlike STOKE, Psyche-C does not have a Docker container. Part of this branch uses Haskell lts-5.1, which is from 2016! Trying to get this running was a nightmare, since modern versions of stack, GHC and cabal could not cope with such an old environment. I was eventually able to get it running by creating an Ubuntu focal docker image but it took me an entire day. I also created a HuggingFace space for it.
I have said it before, but I just love HuggingFace spaces for hosting research artifacts. It makes it almost effortless for others to try out your research. I wish more researchers would use them.
I think that the decompilation and reverse engineering research community could also significantly benefit from using HuggingFace spaces and generally making artifacts easier to use. I say this because there are many subtle details about reverse engineering research artifacts that can make them less usable in practice.
For example, I was recently reading DecompileBench, which is a good paper about benchmarking decompilers. In particular, they have a very clever method for testing whether a decompiled function is semantically equivalent to the original source code. In short, they compile the decompiled function in isolation and splice it into the original program, and do some testing to see if it behaves the same way. I've been thinking about this topic a lot recently, since I have been talking with some of my students about it. The problem is that if the binary is stripped, the decompiler can't refer to symbols by their original name, and thus the decompiled code can't reliably be linked back into the original program. (Ryan pointed out on Bluesky that this is possible in some cases.) DecompileBench ignores this problem and decompiled unstripped binaries. This is a problem, because decompilers are usually used on stripped binaries, and they generally perform significantly worse on them.
My goal is not to criticize DecompileBench; I think it's a nice paper. My point is that there are many subtle details like this that can make research artifacts less useful in practice. I've had my own share. As one example, the DIRT dataset was stripped using the wrong command, so that function names were still present in the binary, which is unrealistic. Fortunately, it turned out (surprisingly) that this did not significantly affect the results in that paper, but it could have.
I think part of the problem with these two examples is that it's hard to get close to the actual use case with these projects. In decompilation, the real use case is decompiling stripped binaries in the wild. But it's hard to run DIRTY on a new binary to see how well it works. I have found this to be a common problem in machine learning-based research. The straight-forward approach is to start with a dataset for which you have ground truth, and then train and test on that dataset. This often leads to preprocessing code that expects to have the ground truth information available. This is problematic when you want to perform inference on a new example when you don't have ground truth information, e.g., the primary use case of these technologies!
My overall message is that docker containers and HuggingFace spaces are great ways to make research artifacts easier to use. This is important in general, but it's also important to be able to get as close to the real use case as possible. If, for example, your technique only works for unstripped binaries and you forget to mention this in your paper, a docker container or space is going to make that very apparent.
I have a pretty hot take: the top-tier conferences should mandate that research artifacts be easy to use, e.g., via docker containers or HuggingFace spaces, on new examples, and that these artifacts should be considered as part of the submission. Having a separate, optional artifact evaluation process simply doesn't work. (The incentive for going through the artifact evaluation is a badge, which is essentially a sticker for grown-ups!) But if reviewers can actually try out the artifact on new examples, they can see how well it works in practice. This would significantly improve the quality of research artifacts in our community.
My colleague Cory Cohen recently asked me to take a look at some surprising behavior in Ghidra's decompiler. He had a decompiled function that looked like this:
/* WARNING: Globals starting with '_' overlap smaller symbols at the same address */
void HI_MPI_SVP_NNIE_LoadModel(model *model_buf,uint *out_buf,ulong param3)
{
uint64_t uVar1;
byte bVar2;
byte bVar3;
ushort uVar4;
ushort uVar5;
short sVar6;
long lVar7;
uint32_t error;
int iVar8;
int flag;
ulong uVar9;
ulong neg_counter;
byte *pbVar10;
byte *pbVar11;
uint uVar12;
ulong uVar13;
uint64_t vir_addr;
long lVar14;
uint uVar15;
ulong uVar16;
byte *local_e8;
uint local_d8;
uint local_d4;
header header_buf;
ulong counter;
uint size;
lVar7 = ___stack_chk_guard;
_header_buf = 0;
error = svp_nnie_check_loadmodel_param_user(model_buf,(long)out_buf);
if (error == 0) {
size = (uint)model_buf->size;
if (size < 0xc1) {
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%u) must be greater than %u!\n "
,"hi_mpi_svp_nnie_load_model",0x345,0xa0338003,(ulong)size,0xc0);
}
else {
vir_addr = model_buf->vir_addr;
memcpy_s(&header_buf,0xc0,vir_addr);
if (false) { fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%d) is less than %d!\n",
"svp_nnie_parse_model_header",0x1b2,0xa0338003);
}
else {
if (false) {
flag = -1;
}
else {
neg_counter = 0;
pbVar10 = (byte *)(vir_addr + 4);
do {
pbVar11 = pbVar10 + 1;
size = *(uint *)(&DAT_00105d70 + ((neg_counter ^ *pbVar10) & 0xff) * 4) ^
(uint)neg_counter >> 8;
neg_counter = (ulong)size;
pbVar10 = pbVar11;
} while ((byte *)(vir_addr + 0x100000000) != pbVar11);
flag = ~size;
}
if (header_buf.unk1 == flag) {
memset_s(out_buf,0x36a8,0);
if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x):model_version(%u) of input model should b e %d!\n"
,"svp_nnie_parse_model_header",0x1c3,0xa0338003,0,0xb);
}
else if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x):arch_version(%u) of input model should be %d!\n"
,"svp_nnie_parse_model_header",0x1c6,0xa0338003);
}
else {
*out_buf = 0;
if (false) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): the run_mode(%d) of input model should be %d!\n"
,"svp_nnie_parse_model_header",0x1d3,0xa0338003,0,0);
}
else {
out_buf[2] = 0;
if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): the net_seg_num(%u) of input model s hould be (0,%d]!\n"
,"svp_nnie_parse_model_header",0x1d7,0xa0338003,0,8);
}
else {
out_buf[1] = 0;
if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): the u32TemBufSize(%u) of input mod el can\'t be 0!\n"
,"svp_nnie_parse_model_header",0x1db,0xa0338003,0);
}
else {
if (true) {
pbVar10 = (byte *)model_buf->vir_addr;
bVar2 = *pbVar10;
size = *(uint *)(pbVar10 + 8);
out_buf[3] = (uint)bVar2;
bVar3 = pbVar10[1];
neg_counter = (ulong)bVar3;
*(ushort *)(out_buf + 4) = (ushort)bVar3;
*(ushort *)((long)out_buf + 0x12) = (ushort)pbVar10[2];
*(ushort *)(out_buf + 5) = (ushort)pbVar10[3];
uVar4 = *(ushort *)(pbVar10 + 4);
out_buf[6] = size;
size = *(uint *)(pbVar10 + 0xc);
*(ushort *)((long)out_buf + 0x16) = uVar4;
out_buf[7] = size;
if (bVar2 < 3) {
local_d8 = 0;
local_d4 = 0;
uVar15 = 0;
local_e8 = pbVar10;
if (bVar3 < 0x11) {
do {
counter = (ulong)local_d4;
lVar14 = counter * 0x69c;
uVar5 = *(ushort *)((long)out_buf + lVar14 + 0x12);
uVar9 = (ulong)uVar5;
if (0x10 < uVar5) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].dst_num(% u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x20d,0xa0338003,(ulong)local_d4,
uVar9,0x10);
goto LAB_001024b8;
}
if (4 < (ushort)out_buf[counter * 0x1a7 + 5]) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].roi_pool_ num(%u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x212,0xa0338003,(ulong)local_d4,
(ulong)(ushort)out_buf[counter * 0x1a7 + 5],4);
goto LAB_001024b8;
}
if (0x400 < uVar4) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].max_step( %u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x216,0xa0338003,(ulong)local_d4,
(ulong)(uint)uVar4,0x400);
goto LAB_001024b8;
}
uVar13 = (ulong)out_buf[counter * 0x1a7 + 6];
if (out_buf[counter * 0x1a7 + 6] != 0) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].inst_offs et(%u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x21c,0xa0338003,(ulong)local_d4,
uVar13,0);
goto LAB_001024b8;
}
if (uVar13 + size != 0) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].inst_offs et(%u)+model->seg[%d].inst_len(%u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x222,0xa0338003,(ulong)local_d4,
uVar13,(ulong)local_d4,size,0);
goto LAB_001024b8;
}
if ((int)neg_counter != 0) {
uVar9 = (ulong)local_d4;
out_buf[uVar9 * 0x1a7 + 10] = *(uint *)(local_e8 + 0x10);
out_buf[uVar9 * 0x1a7 + 9] = *(uint *)(local_e8 + 0x14);
out_buf[uVar9 * 0x1a7 + 0xb] = *(uint *)(local_e8 + 0x18);
uVar4 = *(ushort *)(local_e8 + 0x1e);
neg_counter = (ulong)uVar4;
if ((uVar4 - 2 & 0xfffd) == 0 || 5 < uVar4) {
LAB_00102388:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), the image type(%d) is not supported, image type can\'t be {%d, %d, %d}!\n"
,"svp_nnie_parse_src_node_info",0x248,0xa0338003,neg_counter,2
,4,6);
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): parse %d-th seg src no de failed!\n"
,"hi_mpi_svp_nnie_load_model",0x358,0xa0338003,(ulong)local_d4
);
goto joined_r0x001020c4;
}
size = 0;
uVar13 = 0;
pbVar11 = local_e8 + 0x20;
while( true ) {
uVar12 = (uint)neg_counter;
if (uVar12 == 3) {
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = 2;
sVar6 = *(short *)(pbVar11 + -4);
}
else {
if (uVar12 == 5) {
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = 3;
}
else {
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = uVar12;
}
sVar6 = *(short *)(pbVar11 + -4);
}
if (sVar6 == 1) {
uVar12 = *(uint *)(pbVar11 + -8);
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = 4;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 9] = uVar12;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 0xb] =
*(uint *)(pbVar11 + -0xc);
}
if (size == 0 && out_buf[counter * 0x1a7 + 3] == 2) {
uVar12 = *(uint *)(pbVar11 + -8);
out_buf[uVar9 * 0x1a7 + 8] = 5;
out_buf[uVar9 * 0x1a7 + 9] = uVar12;
}
neg_counter = (ulong)size;
size = size + 1;
strncpy_s(out_buf + neg_counter * 0xd + counter * 0x1a7 + 0xd,0x20,
pbVar11,0x1f);
*(undefined1 *)((long)out_buf + uVar9 * 0x69c + uVar13 * 0x34 + 0x53)
= 0;
neg_counter = (ulong)(ushort)out_buf[counter * 0x1a7 + 4];
if ((ushort)out_buf[counter * 0x1a7 + 4] <= size) break;
uVar13 = (ulong)size;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 10] = *(uint *)(pbVar11 + 0x30)
;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 9] = *(uint *)(pbVar11 + 0x34);
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 0xb] =
*(uint *)(pbVar11 + 0x38);
uVar4 = *(ushort *)(pbVar11 + 0x3e);
neg_counter = (ulong)uVar4;
pbVar11 = pbVar11 + 0x40;
if ((uVar4 - 2 & 0xfffd) == 0 || 5 < uVar4) goto LAB_00102388;
}
uVar9 = (ulong)*(ushort *)((long)out_buf + lVar14 + 0x12);
}
if ((int)uVar9 != 0) {
if (uVar15 < 0xffffffef) {
uVar13 = (ulong)local_d4;
pbVar11 = local_e8 + neg_counter * 0x40 + 0x20;
uVar9 = 0;
LAB_00101f54:
while (pbVar10[(ulong)uVar15 + 0x11] != 1) {
uVar15 = uVar15 + 0x30;
if (uVar15 != 0) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), layer_info_offset( %d) is greater than layer_info_len(%d)!\n"
,"svp_nnie_parse_dst_node_id",0x28e,0xa0338003,
(ulong)uVar15,0);
goto LAB_00102050;
}
}
uVar16 = (ulong)uVar15;
uVar15 = uVar15 + 0x30;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdc] =
(uint)*(ushort *)(pbVar10 + uVar16 + 0x1a);
if (out_buf[counter * 0x1a7 + 3] == 2) {
if (*(short *)(pbVar11 + -4) != 1) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), if net type is %d, the %d-th report data should be tensor!\n"
,"svp_nnie_parse_dst_node_info",700,0,
(ulong)out_buf[counter * 0x1a7 + 3],uVar9);
uVar9 = (ulong)*(ushort *)((long)out_buf + lVar14 + 0x12);
sVar6 = (short)out_buf[counter * 0x1a7 + 5];
goto joined_r0x0010243c;
}
if (*(short *)(pbVar11 + -2) == 1) {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] =
*(uint *)(pbVar11 + -0x10);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 5;
}
else {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xda] = 1;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdb] = 1;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 4;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] =
*(uint *)(pbVar11 + -0x10);
}
}
else {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xda] =
*(uint *)(pbVar11 + -0x10);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] =
*(uint *)(pbVar11 + -0xc);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdb] =
*(uint *)(pbVar11 + -8);
if (*(short *)(pbVar11 + -4) == 0) {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdb] =
*(uint *)(pbVar11 + -0xc);
size = *(uint *)(pbVar11 + -8);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 4;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] = size;
}
else {
if (*(short *)(pbVar11 + -4) != 1) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), report node mode shoule be 0 or 1!\n"
,"svp_nnie_parse_dst_node_info",0x2d6,0);
uVar9 = (ulong)*(ushort *)((long)out_buf + lVar14 + 0x12);
goto LAB_0010218c;
}
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 0;
}
}
size = (int)uVar9 + 1;
uVar16 = (ulong)size;
strncpy_s(out_buf + uVar9 * 0xd + counter * 0x1a7 + 0xdd,0x20,pbVar11,
0x1f);
*(undefined1 *)((long)out_buf + uVar13 * 0x69c + uVar9 * 0x34 + 0x393)
= 0;
uVar4 = *(ushort *)((long)out_buf + lVar14 + 0x12);
uVar9 = (ulong)uVar4;
if (uVar4 <= size) goto LAB_0010218c;
pbVar11 = pbVar11 + 0x40;
uVar9 = uVar16;
if (0xffffffee < uVar15) goto LAB_0010201c;
goto LAB_00101f54;
}
uVar16 = 0;
LAB_0010201c:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), layer_info_offset(%d) sh ould be less than %d!\n"
,"svp_nnie_parse_dst_node_id",0x288,0xa0338003,(ulong)uVar15,
0xffffffef);
uVar9 = uVar16;
LAB_00102050:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), %d-th node, svp_nnie_par se_dst_node_id failed!\n"
,"svp_nnie_parse_dst_node_info",0x2b5,0xa0338003,uVar9);
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): parse %d-th seg dst node failed!\n"
,"hi_mpi_svp_nnie_load_model",0x360,0xa0338003,(ulong)local_d4);
goto joined_r0x001020c4;
}
LAB_0010218c:
sVar6 = (short)out_buf[counter * 0x1a7 + 5];
joined_r0x0010243c:
lVar14 = uVar9 * 0x40 + neg_counter * 0x40 + 0x10;
if (sVar6 == 0) {
uVar4 = 0;
}
else {
neg_counter = 0;
pbVar11 = local_e8 + lVar14 + 0x40;
size = local_d8;
do {
out_buf[(ulong)local_d4 * 0x1a7 + neg_counter + 0x1a8] = size;
uVar12 = (int)neg_counter + 1;
neg_counter = (ulong)uVar12;
local_d8 = size + 1;
out_buf[(ulong)size * 0x1a + 0xd48] = *(uint *)(pbVar11 + -0x40);
out_buf[(ulong)size * 0x1a + 0xd3b] = *(uint *)(pbVar11 + -0x3c);
out_buf[(ulong)size * 0x1a + 0xd3c] = *(uint *)(pbVar11 + -0x38);
out_buf[(ulong)size * 0x1a + 0xd47] = *(uint *)(pbVar11 + -0x34);
out_buf[(ulong)size * 0x1a + 0xd3e] = *(uint *)(pbVar11 + -0x30);
out_buf[(ulong)size * 0x1a + 0xd3f] = *(uint *)(pbVar11 + -0x2c);
out_buf[(ulong)size * 0x1a + 0xd3d] = *(uint *)(pbVar11 + -0x28);
out_buf[(ulong)size * 0x1a + 0xd40] = *(uint *)(pbVar11 + -0x24);
out_buf[(ulong)size * 0x1a + 0xd46] = *(uint *)(pbVar11 + -0x20);
out_buf[(ulong)size * 0x1a + 0xd45] = *(uint *)(pbVar11 + -0x1c);
out_buf[(ulong)size * 0x1a + 0xd41] = *(uint *)(pbVar11 + -0x18);
out_buf[(ulong)size * 0x1a + 0xd42] = *(uint *)(pbVar11 + -0x14);
out_buf[(ulong)size * 0x1a + 0xd43] = *(uint *)(pbVar11 + -0x10);
out_buf[(ulong)size * 0x1a + 0xd44] = *(uint *)(pbVar11 + -0xc);
out_buf[(ulong)size * 0x1a + 0xd49] = (uint)pbVar11[-8];
out_buf[(ulong)size * 0x1a + 0xd4b] = (uint)pbVar11[-7];
out_buf[(ulong)size * 0x1a + 0xd4c] = (uint)pbVar11[-6];
out_buf[(ulong)size * 0x1a + 0xd4a] = (uint)pbVar11[-5];
strncpy_s(out_buf + (ulong)size * 0x1a + 0xd4d,0x20,pbVar11,0x1f);
*(undefined1 *)((long)out_buf + (ulong)size * 0x68 + 0x3553) = 0;
uVar4 = (ushort)out_buf[counter * 0x1a7 + 5];
pbVar11 = pbVar11 + 0x70;
size = local_d8;
} while (uVar12 < uVar4);
}
local_d4 = local_d4 + 1;
local_e8 = local_e8 + (int)((uint)uVar4 * 0x70) + lVar14;
if (out_buf[2] <= local_d4) {
error = 0;
vir_addr = model_buf->phy_addr;
uVar1 = model_buf->vir_addr;
out_buf[0xda8] = 0;
*(uint64_t *)(out_buf + 0xda4) = vir_addr;
*(uint64_t *)(out_buf + 0xda6) = uVar1;
iVar8 = svp_nnie_check_model_user(out_buf);
if (iVar8 != 0) {
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), SVP_NNIE_CheckModelUse r failed!\n"
,"hi_mpi_svp_nnie_load_model",0x371,0xa0338003);
}
goto joined_r0x001020c4;
}
bVar2 = *local_e8;
out_buf[(ulong)local_d4 * 0x1a7 + 3] = (uint)bVar2;
*(ushort *)(out_buf + (ulong)local_d4 * 0x1a7 + 4) = (ushort)local_e8[1];
*(ushort *)((long)out_buf + (ulong)local_d4 * 0x69c + 0x12) =
(ushort)local_e8[2];
*(ushort *)(out_buf + (ulong)local_d4 * 0x1a7 + 5) = (ushort)local_e8[3];
uVar4 = *(ushort *)(local_e8 + 4);
*(ushort *)((long)out_buf + (ulong)local_d4 * 0x69c + 0x16) = uVar4;
out_buf[(ulong)local_d4 * 0x1a7 + 6] = *(uint *)(local_e8 + 8);
size = *(uint *)(local_e8 + 0xc);
out_buf[(ulong)local_d4 * 0x1a7 + 7] = size;
if (2 < bVar2) goto LAB_0010247c;
neg_counter = (ulong)(ushort)out_buf[(ulong)local_d4 * 0x1a7 + 4];
} while ((ushort)out_buf[(ulong)local_d4 * 0x1a7 + 4] < 0x11);
}
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].src_num(%u) can \'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x209,0xa0338003,(ulong)local_d4,
neg_counter,0x10);
}
else {
local_d4 = 0;
LAB_0010247c:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].net_type(%d) sh ould be [%d,%d)!\n"
,"svp_nnie_parse_seg_header",0x205,0xa0338003,(ulong)local_d4,
(ulong)bVar2,0,3);
}
LAB_001024b8:
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): parse %d-th seg head info failed !\n"
,"hi_mpi_svp_nnie_load_model",0x352,0xa0338003,(ulong)local_d4);
goto joined_r0x001020c4;
}
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%u) can\'t be less than %llu!\n"
,"svp_nnie_parse_model_header",0x1e0,0xa0338003);
}
}
}
}
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check file failed!\n",
"svp_nnie_parse_model_header",0x1b5,0xa0338003);
}
}
error = 0xa0338003;
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model head info failed!\n",
"hi_mpi_svp_nnie_load_model",0x347,0xa0338003);
}
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model input param failed!\n",
"hi_mpi_svp_nnie_load_model",0x340,(ulong)error);
}
joined_r0x001020c4:
if (lVar7 == ___stack_chk_guard) {
return;
}
/* WARNING: Subroutine does not return */
__stack_chk_fail(error);
}Cory wanted to know why the decompiler had simplified certain branch conditions
to true or false, such as the one on line 47. Seeing true or false
branch conditions is somewhat rare in decompilers since compilers often perform
these types of optimizations. My first issue was that my decompilation output
looked much shorter than his:
/* WARNING: Removing unreachable block (ram,0x00101c60) */
/* WARNING: Removing unreachable block (ram,0x001026f8) */
/* WARNING: Removing unreachable block (ram,0x00101c6c) */
/* WARNING: Removing unreachable block (ram,0x0010272c) */
/* WARNING: Removing unreachable block (ram,0x00101c58) */
/* WARNING: Removing unreachable block (ram,0x001026c8) */
/* WARNING: Removing unreachable block (ram,0x00101c8c) */
/* WARNING: Removing unreachable block (ram,0x00101cb0) */
/* WARNING: Removing unreachable block (ram,0x00102478) */
/* WARNING: Removing unreachable block (ram,0x00101d0c) */
/* WARNING: Removing unreachable block (ram,0x00101d1c) */
/* WARNING: Removing unreachable block (ram,0x0010264c) */
/* WARNING: Removing unreachable block (ram,0x00101d38) */
/* WARNING: Removing unreachable block (ram,0x00102614) */
/* WARNING: Removing unreachable block (ram,0x00101d44) */
/* WARNING: Removing unreachable block (ram,0x001025d8) */
/* WARNING: Removing unreachable block (ram,0x00101d4c) */
/* WARNING: Removing unreachable block (ram,0x001025a0) */
/* WARNING: Removing unreachable block (ram,0x00101d5c) */
/* WARNING: Removing unreachable block (ram,0x00102560) */
/* WARNING: Removing unreachable block (ram,0x00101d6c) */
/* WARNING: Removing unreachable block (ram,0x00101d70) */
/* WARNING: Removing unreachable block (ram,0x00101db0) */
/* WARNING: Removing unreachable block (ram,0x00101db4) */
/* WARNING: Removing unreachable block (ram,0x00101db8) */
/* WARNING: Removing unreachable block (ram,0x00101e9c) */
/* WARNING: Removing unreachable block (ram,0x00101dd8) */
/* WARNING: Removing unreachable block (ram,0x00101ef0) */
/* WARNING: Removing unreachable block (ram,0x00101de0) */
/* WARNING: Removing unreachable block (ram,0x00101de4) */
/* WARNING: Removing unreachable block (ram,0x00101eb4) */
/* WARNING: Removing unreachable block (ram,0x00101ec8) */
/* WARNING: Removing unreachable block (ram,0x00101df0) */
/* WARNING: Removing unreachable block (ram,0x00101df8) */
/* WARNING: Removing unreachable block (ram,0x00101dfc) */
/* WARNING: Removing unreachable block (ram,0x00101e00) */
/* WARNING: Removing unreachable block (ram,0x00101e10) */
/* WARNING: Removing unreachable block (ram,0x00101efc) */
/* WARNING: Removing unreachable block (ram,0x00101f00) */
/* WARNING: Removing unreachable block (ram,0x00101f1c) */
/* WARNING: Removing unreachable block (ram,0x00101f2c) */
/* WARNING: Removing unreachable block (ram,0x00101f54) */
/* WARNING: Removing unreachable block (ram,0x00101f48) */
/* WARNING: Removing unreachable block (ram,0x001020d0) */
/* WARNING: Removing unreachable block (ram,0x00101f64) */
/* WARNING: Removing unreachable block (ram,0x00102118) */
/* WARNING: Removing unreachable block (ram,0x001023f8) */
/* WARNING: Removing unreachable block (ram,0x00102124) */
/* WARNING: Removing unreachable block (ram,0x0010214c) */
/* WARNING: Removing unreachable block (ram,0x00102130) */
/* WARNING: Removing unreachable block (ram,0x00101f90) */
/* WARNING: Removing unreachable block (ram,0x00102108) */
/* WARNING: Removing unreachable block (ram,0x00102160) */
/* WARNING: Removing unreachable block (ram,0x00102110) */
/* WARNING: Removing unreachable block (ram,0x00101fb0) */
/* WARNING: Removing unreachable block (ram,0x00101fc8) */
/* WARNING: Removing unreachable block (ram,0x0010200c) */
/* WARNING: Removing unreachable block (ram,0x00102558) */
/* WARNING: Removing unreachable block (ram,0x0010201c) */
/* WARNING: Removing unreachable block (ram,0x00102050) */
/* WARNING: Removing unreachable block (ram,0x0010218c) */
/* WARNING: Removing unreachable block (ram,0x00102440) */
/* WARNING: Removing unreachable block (ram,0x001021a4) */
/* WARNING: Removing unreachable block (ram,0x001021bc) */
/* WARNING: Removing unreachable block (ram,0x001022a8) */
/* WARNING: Removing unreachable block (ram,0x001024f0) */
/* WARNING: Removing unreachable block (ram,0x00102520) */
/* WARNING: Removing unreachable block (ram,0x001022d8) */
/* WARNING: Removing unreachable block (ram,0x0010247c) */
/* WARNING: Removing unreachable block (ram,0x00102338) */
/* WARNING: Removing unreachable block (ram,0x00101e50) */
/* WARNING: Removing unreachable block (ram,0x00101e94) */
/* WARNING: Removing unreachable block (ram,0x00101e98) */
/* WARNING: Removing unreachable block (ram,0x00102388) */
/* WARNING: Removing unreachable block (ram,0x00102348) */
/* WARNING: Removing unreachable block (ram,0x001024b8) */
/* WARNING: Removing unreachable block (ram,0x00102800) */
/* WARNING: Removing unreachable block (ram,0x00101c80) */
/* WARNING: Removing unreachable block (ram,0x001027cc) */
/* WARNING: Removing unreachable block (ram,0x00102688) */
/* WARNING: Removing unreachable block (ram,0x0010279c) */
/* WARNING: Globals starting with '_' overlap smaller symbols at the same address */
void HI_MPI_SVP_NNIE_LoadModel(model *model_buf,uint *out_buf,ulong param3)
{
long lVar1;
uint32_t error;
int flag;
ulong neg_counter;
byte *pbVar2;
uint64_t vir_addr;
header header_buf;
byte *pbVar3;
uint size;
lVar1 = ___stack_chk_guard;
_header_buf = 0;
error = svp_nnie_check_loadmodel_param_user(model_buf,(long)out_buf);
if (error == 0) {
size = (uint)model_buf->size;
if (size < 0xc1) {
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%u) must be greater than %u!\n "
,"hi_mpi_svp_nnie_load_model",0x345,0xa0338003,(ulong)size,0xc0);
}
else {
vir_addr = model_buf->vir_addr;
memcpy_s(&header_buf,0xc0,vir_addr);
neg_counter = 0; pbVar3 = (byte *)(vir_addr + 4);
do {
pbVar2 = pbVar3 + 1;
size = *(uint *)(&DAT_00105d70 + ((neg_counter ^ *pbVar3) & 0xff) * 4) ^
(uint)neg_counter >> 8;
neg_counter = (ulong)size;
pbVar3 = pbVar2;
} while ((byte *)(vir_addr + 0x100000000) != pbVar2);
if (header_buf.unk1 == ~size) {
memset_s(out_buf,0x36a8,0);
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x):model_version(%u) of input model should be %d !\n"
,"svp_nnie_parse_model_header",0x1c3,0xa0338003,0,0xb);
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check file failed!\n",
"svp_nnie_parse_model_header",0x1b5,0xa0338003);
}
error = 0xa0338003;
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model head info failed!\n",
"hi_mpi_svp_nnie_load_model",0x347,0xa0338003);
}
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model input param failed!\n",
"hi_mpi_svp_nnie_load_model",0x340,(ulong)error);
}
if (lVar1 == ___stack_chk_guard) {
return;
}
/* WARNING: Subroutine does not return */
__stack_chk_fail(error);
}We figured out that I had the "Eliminate unreachable code" option enabled under Ghidra's Options => Decompiler => Analysis options tab, but he did not.
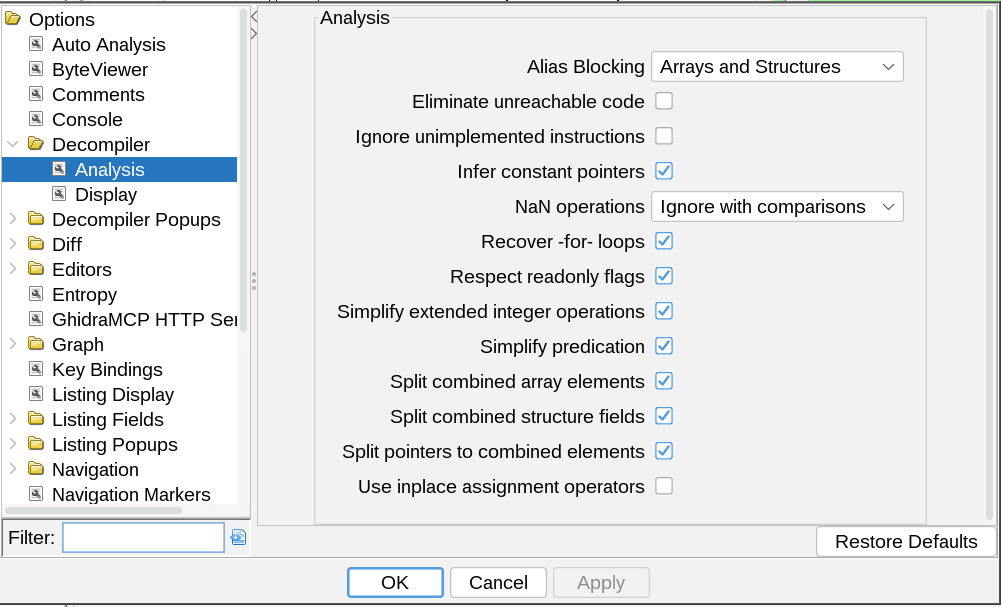
if (false) { ... }
statement was unreachable code and removed it.
With that small mystery solved, I obtained the same decompilation as Cory, but we still didn't know why Ghidra had simplified away the condition. This task was made a lot more challenging since it was an ARM executable, and neither of us are very familiar with ARM assembly code. Cory eventually figured out that on the same decompiler settings tab, changing the "Alias Blocking" option from "Arrays and Structures" to "None" caused Ghidra to preserve the original condition.
Ghidra's documentation on Alias Blocking explains:
When deciding if an individual stack location has become dead, the Decompiler must consider aliases, pointers onto the stack that could be used to modify the location within a called function. One strong heuristic the Decompiler uses is: if the user has explicitly created a variable on the stack between the base location referenced by the pointer and the individual stack location, then the Decompiler can assume that the pointer is not an alias of the stack location. The alias is blocked by the explicit variable. However, if the user's explicit variable is labeling something that isn't really an explicit variable, like a field within a larger structure, for instance, the Decompiler may incorrectly consider the stack location as dead and start removing live code.
In order to support the exploratory labeling of stack locations, the user can use this setting to specify what data-types should be considered blocking. The four options are:
- None - No data-type is considered blocking
- Structures - Only structures are blocking
- Structures and Arrays - Only structures and arrays are blocking
- All Data-types - All data-types are blocking
Selecting None is the equivalent of turning off the heuristic. Selecting anything except All Data-types allows users to safely label small variables without knowing immediately if the stack location is part of a larger structure or array.
To better understand what is going on, here is one of the relevant snippets that went from false to a real condition:
else {
vir_addr = model_buf->vir_addr;
memcpy_s(&header_buf,0xc0,vir_addr);
size = local_98._4_4_ + (uint)uStack_90; if ((uint)model_buf->size < size) { fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%d) is less than %d!\n",
"svp_nnie_parse_model_header",0x1b2,0xa0338003);
}Looking at the stack frame, we can start to piece together what happened:
local_98anduStack_90were initialized to zero.memcpy_swas called with a pointer toheader_buf, which is a structure of size 0xc0 bytes on the stack.- Since
header_bufis a structure, Alias Blocking with "Arrays and Structures" enabled means that Ghidra assumes thatlocal_98anduStack_90cannot be modified by thememcpy_scall, since they are not part of theheader_bufstructure. Therefore, Ghidra concludes that they are unchanged,sizeis always zero, and the condition is alwaysfalse.
Unfortunately for Cory, the header_buf structure he created was only four
bytes long. In reality, local_98 and uStack_90 are fields that are
overwritten by the memcpy_s call, and influence the computation of the
condition. But his artificially small structure misled Ghidra into thinking
they were unaffected.
So What?
I had never heard of the "Alias Blocking" option before, and I'm not aware of a
similar feature in other decompilers. It's an interesting idea though.
Basically, the assumption is that if you have enough information to type an
array or structure on the stack, then it is accurate enough to assume there
won't be pointers from that object that alias outside of that object. There's
also a number of other things that have to work correctly for this analysis to
be correct. If we had confused the calling convention of memcpy_s and did not
detect that it takes a pointer to the stack, then this analysis would also be
incorrect.
It's also interesting because it has the potential to both help and hurt decompilation quality, depending on the situation. Cory noted this functionality could be helpful for deobfuscating opaque predicates, for example. But Cory also noted that he often retypes structs incrementally as he learns more about them. Alias Blocking on structures would actually be harmful for this type of incremental typing.
Anti-analysis?
Another interesting question is whether we can abuse this behavior to make it harder to analyze code. To answer this, I created a small test program that can exhibit the same behavior. Here it is (also on Godbolt):
#include <string.h>
#include <stdio.h>
struct foo {
int blue;
int red;
char green;
float two;
};
void go(struct foo* in) {
int above = -1;
struct foo myfoo;
myfoo.red = 0;
int below = 2;
memcpy(&myfoo, in, sizeof(myfoo));
if (myfoo.red != 10) {
printf("Wow!\n");
}
}
int main() {
struct foo mainfoo = {4, 5, 'a', 3.14};
}I found that I had to compile with gcc -fno-builtin or otherwise gcc would fairly aggressively optimize away the memcpy call!
Upon initially loading Ghidra, the decompilation of the go function looks like this:
/* WARNING: Unknown calling convention -- yet parameter storage is locked */
long go(void)
{
void *in_RDI;
long in_FS_OFFSET;
undefined1 local_28 [4];
int local_24;
long local_10;
local_10 = *(long *)(in_FS_OFFSET + 0x28);
local_24 = 0;
memcpy(local_28,in_RDI,0x10);
if (local_24 != 10) {
printf("Wow!\n");
}
if (local_10 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return 0;
}For some reason undefined1[4] is not considered to be an Array type. But if
we manually retype local_28 to char[4] instead of undefined1[4], we see
the desired behavior:
/* WARNING: Unknown calling convention -- yet parameter storage is locked */
long go(void)
{
long lVar1;
void *in_RDI;
long in_FS_OFFSET;
char local_28 [4];
lVar1 = *(long *)(in_FS_OFFSET + 0x28);
memcpy(local_28,in_RDI,0x10);
if (true) {
printf("Wow!\n");
}
if (lVar1 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return 0;
}Of course, we could have made that condition appear to be false.
If we could nudge Ghidra to type local_28 as a char[4] array automatically,
or a structure, perhaps we could automatically cause Ghidra to misinterpret the
condition. The alias blocking documentation suggests that it only applies when a
user "explicitly" creates a variable on the stack, so this might prevent abuse
for anti-analysis. I leave this as an open question for the reader.


Systematic Testing of C++ Abstraction Recovery Systems by Iterative Compiler Model Refinement
I'm excited to announce that our paper, "Systematic Testing of C++ Abstraction Recovery Systems by Iterative Compiler Model Refinement", has been published at the 2025 Workshop on Software Understanding and Reverse Engineering (SURE)! SURE is a new workshop—more details below.
When I joined SEI, one of my first research projects was improving C++ abstraction recovery from binaries. This work led to the development of OOAnalyzer, a tool that combines practical reverse engineering with academic techniques like a Prolog-based reasoning engine.
Over time, users increasingly adopted OOAnalyze and ran it on video game executables that were much larger and more complex than the malware samples we had originally targeted. Perhaps unsurprisingly, running OOAnalyzer on these larger, more complex binaries often revealed problematic corner cases in OOAnalyzer's rules. As we learned about such problems, we would attempt to improve the rules to handle the new cases. Sometimes this was pretty easy; some of the problems were obvious in hindsight. But not always.
Eventually, I found that some rules were becoming so nuanced and complex that I was having trouble reasoning about them. I realized that I needed a more systematic way to test and refine OOAnalyzer's rules. This realization led to the work presented in this paper.
On one hand, I'm incredibly proud of this paper. To greatly simplify, we developed a way to model check the rules in OOAnalyzer. It's been incredibly effective at finding problems in OOAnalyzer's rules. We found 27 soundness issues in OOAnalyzer, and two in VirtAnalyzer, a competing C++ abstraction recovery system.
Unfortunately, the journey to publication for this paper has been long and bumpy. It is, admittedly, a fairly niche topic. But I also think it has some interesting ideas that could be applied more generally to other reverse engineering systems. In particular, I think that much of what we call "binary analysis" is actually "compiled executable analysis" in disguise. In other words, our binary analyses are often making (substantial!) assumptions about how compilers work, such as the calling conventions that are used, and without these assumptions they do not work. Our paper provides a systematic way to encode and refine these assumptions, and validate whether underlying analyses are correct under the assumptions. My hope is that in future work, we are able to demonstrate how to apply this overall approach to more traditional binary analyses. I personally think that static binary analysis without such reasonable simplifying assumptions is impractical, so we need more techniques like this to help analyze compiled executables.
Although I'm proud of the problems we discovered in OOAnalyzer, I'm also a bit disappointed in the practical impact. My hope was that when we found and fixed soundness problems in OOAnalyzer's rules, it would generally improve the performance of OOAnalyzer on real-world binaries. However, we found that in general this was not true. In fact, in some cases, fixing soundness problems actually made OOAnalyzer perform worse on real-world binaries! I think this highlights that there is a trade-off between soundness and accuracy in binary analysis. In order to be sound, the system can never make mistakes. We may need to make a rule more conservative, even if it almost never poses a problem in practice. However, in order to maximize accuracy, the system must optimize for the most common cases, even if it means that it will occasionally make mistakes.
SURE Workshop
SURE, the Workshop on Software Understanding and Reverse Engineering, is a new workshop colocated with ACM CCS this year. In addition to presenting our paper, I had the honor of participating in a panel on "Modern Software Understanding" alongside Fish Wang and Steffen Enders. The first SURE was a resounding success, and I'm eager to see how it evolves in the coming years!

Powered with by Gatsby 5.0