
I'm happy to announce that my student Luke Dramko's paper "Idioms: A Simple and Effective Framework for Turbo-Charging Local Neural Decompilation with Well-Defined Types" has been accepted to NDSS 2026! Put simply, the paper shows that neural decompilers benefit greatly from explicitly predicting and recovering user-defined types (structs, unions, etc.) referenced in decompiled code.
Paper & Code
- Paper: https://edmcman.github.io/papers/ndss26.pdf
- Code & models: https://github.com/squareslab/idioms
The paper has a great motivating example that I'll borrow here. The example starts with a C function that uses a struct type:
struct hash {
int hash_size;
int item_cnt;
struct gap_array *data;
int (*hash_make_key)(void *item);
int (*cmp_item)(void *item1, void *item2);
};
struct gap_array {
int len;
void **array;
};
int hash_find_index(struct hash *h, void *item) {
void *cnx;
int index = hash_make_key(h, item);
int cnt = 0;
cnx = gap_get(h->data, index);
while (cnx != NULL) {
if (cnt++ > h->hash_size) return -1;
if (!h->cmp_item(cnx, item)) break;
index = hash_next_index(h, index);
cnx = gap_get(h->data, index);
}
if (cnx == NULL) return -1;
return index;
}If you've read this blog, it will probably not surprise you that even state-of-the-art decompilers like Hex-Rays struggle to recover this code in a human-readable form. Here is the output from Hex-Rays:
__int64 __fastcall func4(__int64 a1, __int64 a2) {
int v2; // eax
__int64 result; // rax
int v4; // [rsp+10h] [rbp-10h]
unsigned int v5; // [rsp+14h] [rbp-Ch]
__int64 i; // [rsp+18h] [rbp-8h]
v5 = func2(a1, a2);
v4 = 0;
for (i = func1(*(_QWORD *)(a1 + 8), v5); i;
i = func1(*(_QWORD *)(a1 + 8), v5)) {
v2 = v4++;
if (v2 > *(_DWORD *)a1) return 0xFFFFFFFFLL;
if (!(*(unsigned int(__fastcall **)(__int64, __int64))(a1 + 24))(i, a2))
break;
v5 = func3((_DWORD *)a1, v5);
}
if (i)
result = v5;
else
result = 0xFFFFFFFFLL;
return result;
}There are a lot of problems with this output, but the most serious is that the
information about the hash struct has been completely lost.
A very exciting line of decompilation research is neural decompilation, which leverages neural models to either (1) directly decompile code, or (2) improve the decompiled code from traditional (non-neural) decompilers. I am personally extremely excited about the latter approach, which uses neural models to post-process the output of traditional decompilers such as Hex-Rays. Traditional decompilers have been studied for decades, so why not leverage their strengths while using neural models to fix their weaknesses? One popular example is the LLM4Decompile models. Here is an example of LLM4Decompile's output for this function:
int FUN_00100155(struct FUN_0009ff84 *VAR_0,void *VAR_1){
int VAR_2;
int VAR_3;
void *VAR_4;
VAR_2 = FUN_0009ff86(VAR_0, VAR_1);
VAR_3 = 0;
VAR_4 = FUN_0009ff88(VAR_0->VAR_5, VAR_2);
while (VAR_4) {
if (VAR_0->VAR_6 < VAR_3) { return -1; }
if (!VAR_0->VAR_7(VAR_4, VAR_1)) { break; }
VAR_2 = FUN_0009ff89(VAR_0, VAR_2);
VAR_4 = FUN_0009ff88(VAR_0->VAR_5, VAR_2);
VAR_3++;
}
if (VAR_4) { return VAR_2; }
return -1;
}Unlike Hex-Rays, LLM4Decompile correctly identifies that the function's
arguments are pointers and that the first argument is a pointer to a struct. But
what is struct FUN_0009ff84 and what are its fields, VAR_5, VAR_6, and
VAR_7? And perhaps most importantly for reverse engineers, what offsets are
those fields at? This information is crucial for understanding the code, but
it has been omitted by the model.
One of Idioms' main contributions is to modify the training process of neural models so that they produce well-defined types such as structs with named fields. Unsurprisingly, this makes decompiled code much easier to understand. Here is the output of Idioms on this function:
struct hash_t {
int size;
int count;
struct hash_table_t *table;
int (*hash)(void *key);
int (*cmp)(void *key1, void *key2);
};
struct hash_table_t {
int size;
void **items;
};
int hash_find(struct hash_t *hash, void *key) {
int index = hash_index(hash, key);
int i = 0;
void *item = hash_get(hash->table, index);
while (item != ((void *)0)) {
if (i++ > hash->size) { return -1; }
if (hash->cmp(item, key) == 0) { break; }
index = hash_next(hash, index);
item = hash_get(hash->table, index);
}
return (item == ((void *)0)) ? -1 : index;
}An Unexpected Advantage of Joint Predictions
Perhaps surprisingly, in addition to improving the readability of the code, jointly predicting both code and types also significantly improves the accuracy of the decompiled code!
Across multiple models and evaluation metrics, Idioms consistently outperforms prior neural decompilers:
- On ExeBench: Idioms achieves 54.4% test-pass accuracy (vs. 46.3% for LLM4Decompile and 37.5% for Nova).
- On RealType: A dataset we introduce that contains substantially more and more realistic user-defined types (UDTs); Idioms improves correctness metrics by 95–205% over prior work.
- Context helps: Adding neighboring-function context improves UDT recovery—up to 63% improvement in structural accuracy—with little downside for larger models.
Beyond Decompilation
Surprisingly (to me), Idioms also outperforms standalone type recovery tools such as Retypd, BinSub, TRex, and TypeForge, by at least 73%. This suggests that generative, context-aware approaches may be well suited to resolving the inherent ambiguity of type recovery than prior approaches, even though this was not the original motivation of Idioms.
(Apologies in advance, this is probably going to be rambling.)
I spend a lot of time looking at various research artifacts. Yesterday, I was looking at several verification artifacts, and I was struck by how much impact small details like a Docker container can have. One of the projects I was using is STOKE. STOKE is a cool project, but the salient detail for this post is that it is an abandoned research project. The last commit was in December 2020. This is very common: Ph.D. student creates a project, maintains project, graduates, and then no longer maintains project. Despite that, STOKE has a Docker container, which makes using the project trivial.
In contrast, I was also attempting to run Psyche-C this week. Like STOKE, there's a fair bit of bitrot on the branch that contains the type-inference component. Unlike STOKE, Psyche-C does not have a Docker container. Part of this branch uses Haskell lts-5.1, which is from 2016! Trying to get this running was a nightmare, since modern versions of stack, GHC and cabal could not cope with such an old environment. I was eventually able to get it running by creating an Ubuntu focal docker image but it took me an entire day. I also created a HuggingFace space for it.
I have said it before, but I just love HuggingFace spaces for hosting research artifacts. It makes it almost effortless for others to try out your research. I wish more researchers would use them.
I think that the decompilation and reverse engineering research community could also significantly benefit from using HuggingFace spaces and generally making artifacts easier to use. I say this because there are many subtle details about reverse engineering research artifacts that can make them less usable in practice.
For example, I was recently reading DecompileBench, which is a good paper about benchmarking decompilers. In particular, they have a very clever method for testing whether a decompiled function is semantically equivalent to the original source code. In short, they compile the decompiled function in isolation and splice it into the original program, and do some testing to see if it behaves the same way. I've been thinking about this topic a lot recently, since I have been talking with some of my students about it. The problem is that if the binary is stripped, the decompiler can't refer to symbols by their original name, and thus the decompiled code can't reliably be linked back into the original program. (Ryan pointed out on Bluesky that this is possible in some cases.) DecompileBench ignores this problem and decompiled unstripped binaries. This is a problem, because decompilers are usually used on stripped binaries, and they generally perform significantly worse on them.
My goal is not to criticize DecompileBench; I think it's a nice paper. My point is that there are many subtle details like this that can make research artifacts less useful in practice. I've had my own share. As one example, the DIRT dataset was stripped using the wrong command, so that function names were still present in the binary, which is unrealistic. Fortunately, it turned out (surprisingly) that this did not significantly affect the results in that paper, but it could have.
I think part of the problem with these two examples is that it's hard to get close to the actual use case with these projects. In decompilation, the real use case is decompiling stripped binaries in the wild. But it's hard to run DIRTY on a new binary to see how well it works. I have found this to be a common problem in machine learning-based research. The straight-forward approach is to start with a dataset for which you have ground truth, and then train and test on that dataset. This often leads to preprocessing code that expects to have the ground truth information available. This is problematic when you want to perform inference on a new example when you don't have ground truth information, e.g., the primary use case of these technologies!
My overall message is that docker containers and HuggingFace spaces are great ways to make research artifacts easier to use. This is important in general, but it's also important to be able to get as close to the real use case as possible. If, for example, your technique only works for unstripped binaries and you forget to mention this in your paper, a docker container or space is going to make that very apparent.
I have a pretty hot take: the top-tier conferences should mandate that research artifacts be easy to use, e.g., via docker containers or HuggingFace spaces, on new examples, and that these artifacts should be considered as part of the submission. Having a separate, optional artifact evaluation process simply doesn't work. (The incentive for going through the artifact evaluation is a badge, which is essentially a sticker for grown-ups!) But if reviewers can actually try out the artifact on new examples, they can see how well it works in practice. This would significantly improve the quality of research artifacts in our community.
My colleague Cory Cohen recently asked me to take a look at some surprising behavior in Ghidra's decompiler. He had a decompiled function that looked like this:
/* WARNING: Globals starting with '_' overlap smaller symbols at the same address */
void HI_MPI_SVP_NNIE_LoadModel(model *model_buf,uint *out_buf,ulong param3)
{
uint64_t uVar1;
byte bVar2;
byte bVar3;
ushort uVar4;
ushort uVar5;
short sVar6;
long lVar7;
uint32_t error;
int iVar8;
int flag;
ulong uVar9;
ulong neg_counter;
byte *pbVar10;
byte *pbVar11;
uint uVar12;
ulong uVar13;
uint64_t vir_addr;
long lVar14;
uint uVar15;
ulong uVar16;
byte *local_e8;
uint local_d8;
uint local_d4;
header header_buf;
ulong counter;
uint size;
lVar7 = ___stack_chk_guard;
_header_buf = 0;
error = svp_nnie_check_loadmodel_param_user(model_buf,(long)out_buf);
if (error == 0) {
size = (uint)model_buf->size;
if (size < 0xc1) {
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%u) must be greater than %u!\n "
,"hi_mpi_svp_nnie_load_model",0x345,0xa0338003,(ulong)size,0xc0);
}
else {
vir_addr = model_buf->vir_addr;
memcpy_s(&header_buf,0xc0,vir_addr);
if (false) { fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%d) is less than %d!\n",
"svp_nnie_parse_model_header",0x1b2,0xa0338003);
}
else {
if (false) {
flag = -1;
}
else {
neg_counter = 0;
pbVar10 = (byte *)(vir_addr + 4);
do {
pbVar11 = pbVar10 + 1;
size = *(uint *)(&DAT_00105d70 + ((neg_counter ^ *pbVar10) & 0xff) * 4) ^
(uint)neg_counter >> 8;
neg_counter = (ulong)size;
pbVar10 = pbVar11;
} while ((byte *)(vir_addr + 0x100000000) != pbVar11);
flag = ~size;
}
if (header_buf.unk1 == flag) {
memset_s(out_buf,0x36a8,0);
if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x):model_version(%u) of input model should b e %d!\n"
,"svp_nnie_parse_model_header",0x1c3,0xa0338003,0,0xb);
}
else if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x):arch_version(%u) of input model should be %d!\n"
,"svp_nnie_parse_model_header",0x1c6,0xa0338003);
}
else {
*out_buf = 0;
if (false) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): the run_mode(%d) of input model should be %d!\n"
,"svp_nnie_parse_model_header",0x1d3,0xa0338003,0,0);
}
else {
out_buf[2] = 0;
if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): the net_seg_num(%u) of input model s hould be (0,%d]!\n"
,"svp_nnie_parse_model_header",0x1d7,0xa0338003,0,8);
}
else {
out_buf[1] = 0;
if (true) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): the u32TemBufSize(%u) of input mod el can\'t be 0!\n"
,"svp_nnie_parse_model_header",0x1db,0xa0338003,0);
}
else {
if (true) {
pbVar10 = (byte *)model_buf->vir_addr;
bVar2 = *pbVar10;
size = *(uint *)(pbVar10 + 8);
out_buf[3] = (uint)bVar2;
bVar3 = pbVar10[1];
neg_counter = (ulong)bVar3;
*(ushort *)(out_buf + 4) = (ushort)bVar3;
*(ushort *)((long)out_buf + 0x12) = (ushort)pbVar10[2];
*(ushort *)(out_buf + 5) = (ushort)pbVar10[3];
uVar4 = *(ushort *)(pbVar10 + 4);
out_buf[6] = size;
size = *(uint *)(pbVar10 + 0xc);
*(ushort *)((long)out_buf + 0x16) = uVar4;
out_buf[7] = size;
if (bVar2 < 3) {
local_d8 = 0;
local_d4 = 0;
uVar15 = 0;
local_e8 = pbVar10;
if (bVar3 < 0x11) {
do {
counter = (ulong)local_d4;
lVar14 = counter * 0x69c;
uVar5 = *(ushort *)((long)out_buf + lVar14 + 0x12);
uVar9 = (ulong)uVar5;
if (0x10 < uVar5) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].dst_num(% u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x20d,0xa0338003,(ulong)local_d4,
uVar9,0x10);
goto LAB_001024b8;
}
if (4 < (ushort)out_buf[counter * 0x1a7 + 5]) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].roi_pool_ num(%u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x212,0xa0338003,(ulong)local_d4,
(ulong)(ushort)out_buf[counter * 0x1a7 + 5],4);
goto LAB_001024b8;
}
if (0x400 < uVar4) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].max_step( %u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x216,0xa0338003,(ulong)local_d4,
(ulong)(uint)uVar4,0x400);
goto LAB_001024b8;
}
uVar13 = (ulong)out_buf[counter * 0x1a7 + 6];
if (out_buf[counter * 0x1a7 + 6] != 0) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].inst_offs et(%u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x21c,0xa0338003,(ulong)local_d4,
uVar13,0);
goto LAB_001024b8;
}
if (uVar13 + size != 0) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].inst_offs et(%u)+model->seg[%d].inst_len(%u) can\'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x222,0xa0338003,(ulong)local_d4,
uVar13,(ulong)local_d4,size,0);
goto LAB_001024b8;
}
if ((int)neg_counter != 0) {
uVar9 = (ulong)local_d4;
out_buf[uVar9 * 0x1a7 + 10] = *(uint *)(local_e8 + 0x10);
out_buf[uVar9 * 0x1a7 + 9] = *(uint *)(local_e8 + 0x14);
out_buf[uVar9 * 0x1a7 + 0xb] = *(uint *)(local_e8 + 0x18);
uVar4 = *(ushort *)(local_e8 + 0x1e);
neg_counter = (ulong)uVar4;
if ((uVar4 - 2 & 0xfffd) == 0 || 5 < uVar4) {
LAB_00102388:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), the image type(%d) is not supported, image type can\'t be {%d, %d, %d}!\n"
,"svp_nnie_parse_src_node_info",0x248,0xa0338003,neg_counter,2
,4,6);
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): parse %d-th seg src no de failed!\n"
,"hi_mpi_svp_nnie_load_model",0x358,0xa0338003,(ulong)local_d4
);
goto joined_r0x001020c4;
}
size = 0;
uVar13 = 0;
pbVar11 = local_e8 + 0x20;
while( true ) {
uVar12 = (uint)neg_counter;
if (uVar12 == 3) {
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = 2;
sVar6 = *(short *)(pbVar11 + -4);
}
else {
if (uVar12 == 5) {
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = 3;
}
else {
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = uVar12;
}
sVar6 = *(short *)(pbVar11 + -4);
}
if (sVar6 == 1) {
uVar12 = *(uint *)(pbVar11 + -8);
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 8] = 4;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 9] = uVar12;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 0xb] =
*(uint *)(pbVar11 + -0xc);
}
if (size == 0 && out_buf[counter * 0x1a7 + 3] == 2) {
uVar12 = *(uint *)(pbVar11 + -8);
out_buf[uVar9 * 0x1a7 + 8] = 5;
out_buf[uVar9 * 0x1a7 + 9] = uVar12;
}
neg_counter = (ulong)size;
size = size + 1;
strncpy_s(out_buf + neg_counter * 0xd + counter * 0x1a7 + 0xd,0x20,
pbVar11,0x1f);
*(undefined1 *)((long)out_buf + uVar9 * 0x69c + uVar13 * 0x34 + 0x53)
= 0;
neg_counter = (ulong)(ushort)out_buf[counter * 0x1a7 + 4];
if ((ushort)out_buf[counter * 0x1a7 + 4] <= size) break;
uVar13 = (ulong)size;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 10] = *(uint *)(pbVar11 + 0x30)
;
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 9] = *(uint *)(pbVar11 + 0x34);
out_buf[uVar13 * 0xd + uVar9 * 0x1a7 + 0xb] =
*(uint *)(pbVar11 + 0x38);
uVar4 = *(ushort *)(pbVar11 + 0x3e);
neg_counter = (ulong)uVar4;
pbVar11 = pbVar11 + 0x40;
if ((uVar4 - 2 & 0xfffd) == 0 || 5 < uVar4) goto LAB_00102388;
}
uVar9 = (ulong)*(ushort *)((long)out_buf + lVar14 + 0x12);
}
if ((int)uVar9 != 0) {
if (uVar15 < 0xffffffef) {
uVar13 = (ulong)local_d4;
pbVar11 = local_e8 + neg_counter * 0x40 + 0x20;
uVar9 = 0;
LAB_00101f54:
while (pbVar10[(ulong)uVar15 + 0x11] != 1) {
uVar15 = uVar15 + 0x30;
if (uVar15 != 0) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), layer_info_offset( %d) is greater than layer_info_len(%d)!\n"
,"svp_nnie_parse_dst_node_id",0x28e,0xa0338003,
(ulong)uVar15,0);
goto LAB_00102050;
}
}
uVar16 = (ulong)uVar15;
uVar15 = uVar15 + 0x30;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdc] =
(uint)*(ushort *)(pbVar10 + uVar16 + 0x1a);
if (out_buf[counter * 0x1a7 + 3] == 2) {
if (*(short *)(pbVar11 + -4) != 1) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), if net type is %d, the %d-th report data should be tensor!\n"
,"svp_nnie_parse_dst_node_info",700,0,
(ulong)out_buf[counter * 0x1a7 + 3],uVar9);
uVar9 = (ulong)*(ushort *)((long)out_buf + lVar14 + 0x12);
sVar6 = (short)out_buf[counter * 0x1a7 + 5];
goto joined_r0x0010243c;
}
if (*(short *)(pbVar11 + -2) == 1) {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] =
*(uint *)(pbVar11 + -0x10);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 5;
}
else {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xda] = 1;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdb] = 1;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 4;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] =
*(uint *)(pbVar11 + -0x10);
}
}
else {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xda] =
*(uint *)(pbVar11 + -0x10);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] =
*(uint *)(pbVar11 + -0xc);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdb] =
*(uint *)(pbVar11 + -8);
if (*(short *)(pbVar11 + -4) == 0) {
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xdb] =
*(uint *)(pbVar11 + -0xc);
size = *(uint *)(pbVar11 + -8);
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 4;
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd9] = size;
}
else {
if (*(short *)(pbVar11 + -4) != 1) {
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), report node mode shoule be 0 or 1!\n"
,"svp_nnie_parse_dst_node_info",0x2d6,0);
uVar9 = (ulong)*(ushort *)((long)out_buf + lVar14 + 0x12);
goto LAB_0010218c;
}
out_buf[uVar9 * 0xd + uVar13 * 0x1a7 + 0xd8] = 0;
}
}
size = (int)uVar9 + 1;
uVar16 = (ulong)size;
strncpy_s(out_buf + uVar9 * 0xd + counter * 0x1a7 + 0xdd,0x20,pbVar11,
0x1f);
*(undefined1 *)((long)out_buf + uVar13 * 0x69c + uVar9 * 0x34 + 0x393)
= 0;
uVar4 = *(ushort *)((long)out_buf + lVar14 + 0x12);
uVar9 = (ulong)uVar4;
if (uVar4 <= size) goto LAB_0010218c;
pbVar11 = pbVar11 + 0x40;
uVar9 = uVar16;
if (0xffffffee < uVar15) goto LAB_0010201c;
goto LAB_00101f54;
}
uVar16 = 0;
LAB_0010201c:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), layer_info_offset(%d) sh ould be less than %d!\n"
,"svp_nnie_parse_dst_node_id",0x288,0xa0338003,(ulong)uVar15,
0xffffffef);
uVar9 = uVar16;
LAB_00102050:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), %d-th node, svp_nnie_par se_dst_node_id failed!\n"
,"svp_nnie_parse_dst_node_info",0x2b5,0xa0338003,uVar9);
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): parse %d-th seg dst node failed!\n"
,"hi_mpi_svp_nnie_load_model",0x360,0xa0338003,(ulong)local_d4);
goto joined_r0x001020c4;
}
LAB_0010218c:
sVar6 = (short)out_buf[counter * 0x1a7 + 5];
joined_r0x0010243c:
lVar14 = uVar9 * 0x40 + neg_counter * 0x40 + 0x10;
if (sVar6 == 0) {
uVar4 = 0;
}
else {
neg_counter = 0;
pbVar11 = local_e8 + lVar14 + 0x40;
size = local_d8;
do {
out_buf[(ulong)local_d4 * 0x1a7 + neg_counter + 0x1a8] = size;
uVar12 = (int)neg_counter + 1;
neg_counter = (ulong)uVar12;
local_d8 = size + 1;
out_buf[(ulong)size * 0x1a + 0xd48] = *(uint *)(pbVar11 + -0x40);
out_buf[(ulong)size * 0x1a + 0xd3b] = *(uint *)(pbVar11 + -0x3c);
out_buf[(ulong)size * 0x1a + 0xd3c] = *(uint *)(pbVar11 + -0x38);
out_buf[(ulong)size * 0x1a + 0xd47] = *(uint *)(pbVar11 + -0x34);
out_buf[(ulong)size * 0x1a + 0xd3e] = *(uint *)(pbVar11 + -0x30);
out_buf[(ulong)size * 0x1a + 0xd3f] = *(uint *)(pbVar11 + -0x2c);
out_buf[(ulong)size * 0x1a + 0xd3d] = *(uint *)(pbVar11 + -0x28);
out_buf[(ulong)size * 0x1a + 0xd40] = *(uint *)(pbVar11 + -0x24);
out_buf[(ulong)size * 0x1a + 0xd46] = *(uint *)(pbVar11 + -0x20);
out_buf[(ulong)size * 0x1a + 0xd45] = *(uint *)(pbVar11 + -0x1c);
out_buf[(ulong)size * 0x1a + 0xd41] = *(uint *)(pbVar11 + -0x18);
out_buf[(ulong)size * 0x1a + 0xd42] = *(uint *)(pbVar11 + -0x14);
out_buf[(ulong)size * 0x1a + 0xd43] = *(uint *)(pbVar11 + -0x10);
out_buf[(ulong)size * 0x1a + 0xd44] = *(uint *)(pbVar11 + -0xc);
out_buf[(ulong)size * 0x1a + 0xd49] = (uint)pbVar11[-8];
out_buf[(ulong)size * 0x1a + 0xd4b] = (uint)pbVar11[-7];
out_buf[(ulong)size * 0x1a + 0xd4c] = (uint)pbVar11[-6];
out_buf[(ulong)size * 0x1a + 0xd4a] = (uint)pbVar11[-5];
strncpy_s(out_buf + (ulong)size * 0x1a + 0xd4d,0x20,pbVar11,0x1f);
*(undefined1 *)((long)out_buf + (ulong)size * 0x68 + 0x3553) = 0;
uVar4 = (ushort)out_buf[counter * 0x1a7 + 5];
pbVar11 = pbVar11 + 0x70;
size = local_d8;
} while (uVar12 < uVar4);
}
local_d4 = local_d4 + 1;
local_e8 = local_e8 + (int)((uint)uVar4 * 0x70) + lVar14;
if (out_buf[2] <= local_d4) {
error = 0;
vir_addr = model_buf->phy_addr;
uVar1 = model_buf->vir_addr;
out_buf[0xda8] = 0;
*(uint64_t *)(out_buf + 0xda4) = vir_addr;
*(uint64_t *)(out_buf + 0xda6) = uVar1;
iVar8 = svp_nnie_check_model_user(out_buf);
if (iVar8 != 0) {
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x), SVP_NNIE_CheckModelUse r failed!\n"
,"hi_mpi_svp_nnie_load_model",0x371,0xa0338003);
}
goto joined_r0x001020c4;
}
bVar2 = *local_e8;
out_buf[(ulong)local_d4 * 0x1a7 + 3] = (uint)bVar2;
*(ushort *)(out_buf + (ulong)local_d4 * 0x1a7 + 4) = (ushort)local_e8[1];
*(ushort *)((long)out_buf + (ulong)local_d4 * 0x69c + 0x12) =
(ushort)local_e8[2];
*(ushort *)(out_buf + (ulong)local_d4 * 0x1a7 + 5) = (ushort)local_e8[3];
uVar4 = *(ushort *)(local_e8 + 4);
*(ushort *)((long)out_buf + (ulong)local_d4 * 0x69c + 0x16) = uVar4;
out_buf[(ulong)local_d4 * 0x1a7 + 6] = *(uint *)(local_e8 + 8);
size = *(uint *)(local_e8 + 0xc);
out_buf[(ulong)local_d4 * 0x1a7 + 7] = size;
if (2 < bVar2) goto LAB_0010247c;
neg_counter = (ulong)(ushort)out_buf[(ulong)local_d4 * 0x1a7 + 4];
} while ((ushort)out_buf[(ulong)local_d4 * 0x1a7 + 4] < 0x11);
}
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].src_num(%u) can \'t be greater than %u!\n"
,"svp_nnie_parse_seg_header",0x209,0xa0338003,(ulong)local_d4,
neg_counter,0x10);
}
else {
local_d4 = 0;
LAB_0010247c:
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model->seg[%d].net_type(%d) sh ould be [%d,%d)!\n"
,"svp_nnie_parse_seg_header",0x205,0xa0338003,(ulong)local_d4,
(ulong)bVar2,0,3);
}
LAB_001024b8:
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): parse %d-th seg head info failed !\n"
,"hi_mpi_svp_nnie_load_model",0x352,0xa0338003,(ulong)local_d4);
goto joined_r0x001020c4;
}
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%u) can\'t be less than %llu!\n"
,"svp_nnie_parse_model_header",0x1e0,0xa0338003);
}
}
}
}
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check file failed!\n",
"svp_nnie_parse_model_header",0x1b5,0xa0338003);
}
}
error = 0xa0338003;
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model head info failed!\n",
"hi_mpi_svp_nnie_load_model",0x347,0xa0338003);
}
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model input param failed!\n",
"hi_mpi_svp_nnie_load_model",0x340,(ulong)error);
}
joined_r0x001020c4:
if (lVar7 == ___stack_chk_guard) {
return;
}
/* WARNING: Subroutine does not return */
__stack_chk_fail(error);
}Cory wanted to know why the decompiler had simplified certain branch conditions
to true or false, such as the one on line 47. Seeing true or false
branch conditions is somewhat rare in decompilers since compilers often perform
these types of optimizations. My first issue was that my decompilation output
looked much shorter than his:
/* WARNING: Removing unreachable block (ram,0x00101c60) */
/* WARNING: Removing unreachable block (ram,0x001026f8) */
/* WARNING: Removing unreachable block (ram,0x00101c6c) */
/* WARNING: Removing unreachable block (ram,0x0010272c) */
/* WARNING: Removing unreachable block (ram,0x00101c58) */
/* WARNING: Removing unreachable block (ram,0x001026c8) */
/* WARNING: Removing unreachable block (ram,0x00101c8c) */
/* WARNING: Removing unreachable block (ram,0x00101cb0) */
/* WARNING: Removing unreachable block (ram,0x00102478) */
/* WARNING: Removing unreachable block (ram,0x00101d0c) */
/* WARNING: Removing unreachable block (ram,0x00101d1c) */
/* WARNING: Removing unreachable block (ram,0x0010264c) */
/* WARNING: Removing unreachable block (ram,0x00101d38) */
/* WARNING: Removing unreachable block (ram,0x00102614) */
/* WARNING: Removing unreachable block (ram,0x00101d44) */
/* WARNING: Removing unreachable block (ram,0x001025d8) */
/* WARNING: Removing unreachable block (ram,0x00101d4c) */
/* WARNING: Removing unreachable block (ram,0x001025a0) */
/* WARNING: Removing unreachable block (ram,0x00101d5c) */
/* WARNING: Removing unreachable block (ram,0x00102560) */
/* WARNING: Removing unreachable block (ram,0x00101d6c) */
/* WARNING: Removing unreachable block (ram,0x00101d70) */
/* WARNING: Removing unreachable block (ram,0x00101db0) */
/* WARNING: Removing unreachable block (ram,0x00101db4) */
/* WARNING: Removing unreachable block (ram,0x00101db8) */
/* WARNING: Removing unreachable block (ram,0x00101e9c) */
/* WARNING: Removing unreachable block (ram,0x00101dd8) */
/* WARNING: Removing unreachable block (ram,0x00101ef0) */
/* WARNING: Removing unreachable block (ram,0x00101de0) */
/* WARNING: Removing unreachable block (ram,0x00101de4) */
/* WARNING: Removing unreachable block (ram,0x00101eb4) */
/* WARNING: Removing unreachable block (ram,0x00101ec8) */
/* WARNING: Removing unreachable block (ram,0x00101df0) */
/* WARNING: Removing unreachable block (ram,0x00101df8) */
/* WARNING: Removing unreachable block (ram,0x00101dfc) */
/* WARNING: Removing unreachable block (ram,0x00101e00) */
/* WARNING: Removing unreachable block (ram,0x00101e10) */
/* WARNING: Removing unreachable block (ram,0x00101efc) */
/* WARNING: Removing unreachable block (ram,0x00101f00) */
/* WARNING: Removing unreachable block (ram,0x00101f1c) */
/* WARNING: Removing unreachable block (ram,0x00101f2c) */
/* WARNING: Removing unreachable block (ram,0x00101f54) */
/* WARNING: Removing unreachable block (ram,0x00101f48) */
/* WARNING: Removing unreachable block (ram,0x001020d0) */
/* WARNING: Removing unreachable block (ram,0x00101f64) */
/* WARNING: Removing unreachable block (ram,0x00102118) */
/* WARNING: Removing unreachable block (ram,0x001023f8) */
/* WARNING: Removing unreachable block (ram,0x00102124) */
/* WARNING: Removing unreachable block (ram,0x0010214c) */
/* WARNING: Removing unreachable block (ram,0x00102130) */
/* WARNING: Removing unreachable block (ram,0x00101f90) */
/* WARNING: Removing unreachable block (ram,0x00102108) */
/* WARNING: Removing unreachable block (ram,0x00102160) */
/* WARNING: Removing unreachable block (ram,0x00102110) */
/* WARNING: Removing unreachable block (ram,0x00101fb0) */
/* WARNING: Removing unreachable block (ram,0x00101fc8) */
/* WARNING: Removing unreachable block (ram,0x0010200c) */
/* WARNING: Removing unreachable block (ram,0x00102558) */
/* WARNING: Removing unreachable block (ram,0x0010201c) */
/* WARNING: Removing unreachable block (ram,0x00102050) */
/* WARNING: Removing unreachable block (ram,0x0010218c) */
/* WARNING: Removing unreachable block (ram,0x00102440) */
/* WARNING: Removing unreachable block (ram,0x001021a4) */
/* WARNING: Removing unreachable block (ram,0x001021bc) */
/* WARNING: Removing unreachable block (ram,0x001022a8) */
/* WARNING: Removing unreachable block (ram,0x001024f0) */
/* WARNING: Removing unreachable block (ram,0x00102520) */
/* WARNING: Removing unreachable block (ram,0x001022d8) */
/* WARNING: Removing unreachable block (ram,0x0010247c) */
/* WARNING: Removing unreachable block (ram,0x00102338) */
/* WARNING: Removing unreachable block (ram,0x00101e50) */
/* WARNING: Removing unreachable block (ram,0x00101e94) */
/* WARNING: Removing unreachable block (ram,0x00101e98) */
/* WARNING: Removing unreachable block (ram,0x00102388) */
/* WARNING: Removing unreachable block (ram,0x00102348) */
/* WARNING: Removing unreachable block (ram,0x001024b8) */
/* WARNING: Removing unreachable block (ram,0x00102800) */
/* WARNING: Removing unreachable block (ram,0x00101c80) */
/* WARNING: Removing unreachable block (ram,0x001027cc) */
/* WARNING: Removing unreachable block (ram,0x00102688) */
/* WARNING: Removing unreachable block (ram,0x0010279c) */
/* WARNING: Globals starting with '_' overlap smaller symbols at the same address */
void HI_MPI_SVP_NNIE_LoadModel(model *model_buf,uint *out_buf,ulong param3)
{
long lVar1;
uint32_t error;
int flag;
ulong neg_counter;
byte *pbVar2;
uint64_t vir_addr;
header header_buf;
byte *pbVar3;
uint size;
lVar1 = ___stack_chk_guard;
_header_buf = 0;
error = svp_nnie_check_loadmodel_param_user(model_buf,(long)out_buf);
if (error == 0) {
size = (uint)model_buf->size;
if (size < 0xc1) {
error = 0xa0338003;
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%u) must be greater than %u!\n "
,"hi_mpi_svp_nnie_load_model",0x345,0xa0338003,(ulong)size,0xc0);
}
else {
vir_addr = model_buf->vir_addr;
memcpy_s(&header_buf,0xc0,vir_addr);
neg_counter = 0; pbVar3 = (byte *)(vir_addr + 4);
do {
pbVar2 = pbVar3 + 1;
size = *(uint *)(&DAT_00105d70 + ((neg_counter ^ *pbVar3) & 0xff) * 4) ^
(uint)neg_counter >> 8;
neg_counter = (ulong)size;
pbVar3 = pbVar2;
} while ((byte *)(vir_addr + 0x100000000) != pbVar2);
if (header_buf.unk1 == ~size) {
memset_s(out_buf,0x36a8,0);
fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x):model_version(%u) of input model should be %d !\n"
,"svp_nnie_parse_model_header",0x1c3,0xa0338003,0,0xb);
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check file failed!\n",
"svp_nnie_parse_model_header",0x1b5,0xa0338003);
}
error = 0xa0338003;
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model head info failed!\n",
"hi_mpi_svp_nnie_load_model",0x347,0xa0338003);
}
}
else {
fprintf(_stderr,"[Func]:%s [Line]:%d [Info]:Error(%#x): check model input param failed!\n",
"hi_mpi_svp_nnie_load_model",0x340,(ulong)error);
}
if (lVar1 == ___stack_chk_guard) {
return;
}
/* WARNING: Subroutine does not return */
__stack_chk_fail(error);
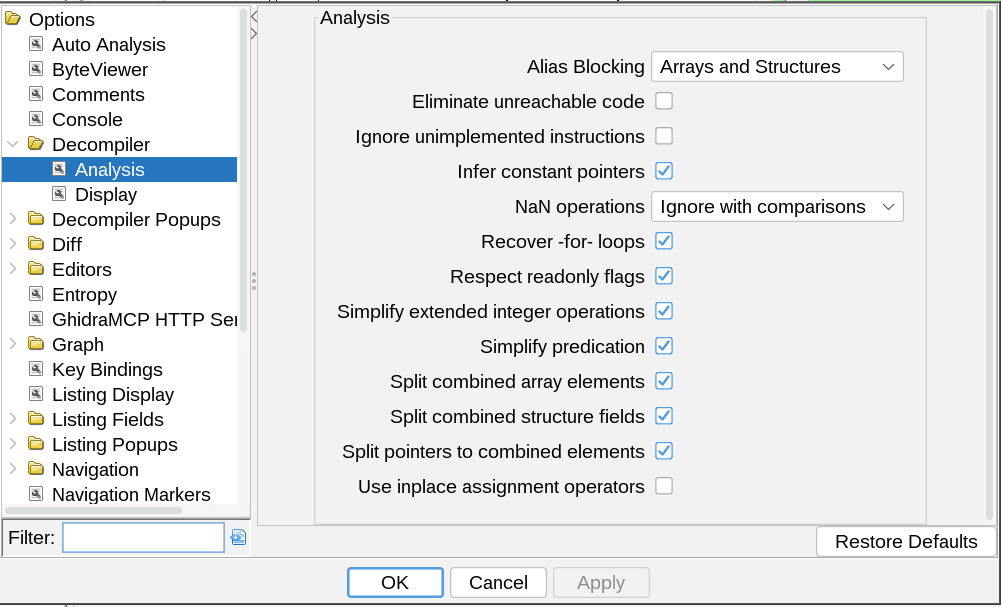
}We figured out that I had the "Eliminate unreachable code" option enabled under Ghidra's Options => Decompiler => Analysis options tab, but he did not.
if (false) { ... }
statement was unreachable code and removed it.
With that small mystery solved, I obtained the same decompilation as Cory, but we still didn't know why Ghidra had simplified away the condition. This task was made a lot more challenging since it was an ARM executable, and neither of us are very familiar with ARM assembly code. Cory eventually figured out that on the same decompiler settings tab, changing the "Alias Blocking" option from "Arrays and Structures" to "None" caused Ghidra to preserve the original condition.
Ghidra's documentation on Alias Blocking explains:
When deciding if an individual stack location has become dead, the Decompiler must consider aliases, pointers onto the stack that could be used to modify the location within a called function. One strong heuristic the Decompiler uses is: if the user has explicitly created a variable on the stack between the base location referenced by the pointer and the individual stack location, then the Decompiler can assume that the pointer is not an alias of the stack location. The alias is blocked by the explicit variable. However, if the user's explicit variable is labeling something that isn't really an explicit variable, like a field within a larger structure, for instance, the Decompiler may incorrectly consider the stack location as dead and start removing live code.
In order to support the exploratory labeling of stack locations, the user can use this setting to specify what data-types should be considered blocking. The four options are:
- None - No data-type is considered blocking
- Structures - Only structures are blocking
- Structures and Arrays - Only structures and arrays are blocking
- All Data-types - All data-types are blocking
Selecting None is the equivalent of turning off the heuristic. Selecting anything except All Data-types allows users to safely label small variables without knowing immediately if the stack location is part of a larger structure or array.
To better understand what is going on, here is one of the relevant snippets that went from false to a real condition:
else {
vir_addr = model_buf->vir_addr;
memcpy_s(&header_buf,0xc0,vir_addr);
size = local_98._4_4_ + (uint)uStack_90; if ((uint)model_buf->size < size) { fprintf(_stderr,
"[Func]:%s [Line]:%d [Info]:Error(%#x): model_buf->size(%d) is less than %d!\n",
"svp_nnie_parse_model_header",0x1b2,0xa0338003);
}Looking at the stack frame, we can start to piece together what happened:
local_98anduStack_90were initialized to zero.memcpy_swas called with a pointer toheader_buf, which is a structure of size 0xc0 bytes on the stack.- Since
header_bufis a structure, Alias Blocking with "Arrays and Structures" enabled means that Ghidra assumes thatlocal_98anduStack_90cannot be modified by thememcpy_scall, since they are not part of theheader_bufstructure. Therefore, Ghidra concludes that they are unchanged,sizeis always zero, and the condition is alwaysfalse.
Unfortunately for Cory, the header_buf structure he created was only four
bytes long. In reality, local_98 and uStack_90 are fields that are
overwritten by the memcpy_s call, and influence the computation of the
condition. But his artificially small structure misled Ghidra into thinking
they were unaffected.
So What?
I had never heard of the "Alias Blocking" option before, and I'm not aware of a
similar feature in other decompilers. It's an interesting idea though.
Basically, the assumption is that if you have enough information to type an
array or structure on the stack, then it is accurate enough to assume there
won't be pointers from that object that alias outside of that object. There's
also a number of other things that have to work correctly for this analysis to
be correct. If we had confused the calling convention of memcpy_s and did not
detect that it takes a pointer to the stack, then this analysis would also be
incorrect.
It's also interesting because it has the potential to both help and hurt decompilation quality, depending on the situation. Cory noted this functionality could be helpful for deobfuscating opaque predicates, for example. But Cory also noted that he often retypes structs incrementally as he learns more about them. Alias Blocking on structures would actually be harmful for this type of incremental typing.
Anti-analysis?
Another interesting question is whether we can abuse this behavior to make it harder to analyze code. To answer this, I created a small test program that can exhibit the same behavior. Here it is (also on Godbolt):
#include <string.h>
#include <stdio.h>
struct foo {
int blue;
int red;
char green;
float two;
};
void go(struct foo* in) {
int above = -1;
struct foo myfoo;
myfoo.red = 0;
int below = 2;
memcpy(&myfoo, in, sizeof(myfoo));
if (myfoo.red != 10) {
printf("Wow!\n");
}
}
int main() {
struct foo mainfoo = {4, 5, 'a', 3.14};
}I found that I had to compile with gcc -fno-builtin or otherwise gcc would fairly aggressively optimize away the memcpy call!
Upon initially loading Ghidra, the decompilation of the go function looks like this:
/* WARNING: Unknown calling convention -- yet parameter storage is locked */
long go(void)
{
void *in_RDI;
long in_FS_OFFSET;
undefined1 local_28 [4];
int local_24;
long local_10;
local_10 = *(long *)(in_FS_OFFSET + 0x28);
local_24 = 0;
memcpy(local_28,in_RDI,0x10);
if (local_24 != 10) {
printf("Wow!\n");
}
if (local_10 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return 0;
}For some reason undefined1[4] is not considered to be an Array type. But if
we manually retype local_28 to char[4] instead of undefined1[4], we see
the desired behavior:
/* WARNING: Unknown calling convention -- yet parameter storage is locked */
long go(void)
{
long lVar1;
void *in_RDI;
long in_FS_OFFSET;
char local_28 [4];
lVar1 = *(long *)(in_FS_OFFSET + 0x28);
memcpy(local_28,in_RDI,0x10);
if (true) {
printf("Wow!\n");
}
if (lVar1 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return 0;
}Of course, we could have made that condition appear to be false.
If we could nudge Ghidra to type local_28 as a char[4] array automatically,
or a structure, perhaps we could automatically cause Ghidra to misinterpret the
condition. The alias blocking documentation suggests that it only applies when a
user "explicitly" creates a variable on the stack, so this might prevent abuse
for anti-analysis. I leave this as an open question for the reader.


Systematic Testing of C++ Abstraction Recovery Systems by Iterative Compiler Model Refinement
I'm excited to announce that our paper, "Systematic Testing of C++ Abstraction Recovery Systems by Iterative Compiler Model Refinement", has been published at the 2025 Workshop on Software Understanding and Reverse Engineering (SURE)! SURE is a new workshop—more details below.
When I joined SEI, one of my first research projects was improving C++ abstraction recovery from binaries. This work led to the development of OOAnalyzer, a tool that combines practical reverse engineering with academic techniques like a Prolog-based reasoning engine.
Over time, users increasingly adopted OOAnalyze and ran it on video game executables that were much larger and more complex than the malware samples we had originally targeted. Perhaps unsurprisingly, running OOAnalyzer on these larger, more complex binaries often revealed problematic corner cases in OOAnalyzer's rules. As we learned about such problems, we would attempt to improve the rules to handle the new cases. Sometimes this was pretty easy; some of the problems were obvious in hindsight. But not always.
Eventually, I found that some rules were becoming so nuanced and complex that I was having trouble reasoning about them. I realized that I needed a more systematic way to test and refine OOAnalyzer's rules. This realization led to the work presented in this paper.
On one hand, I'm incredibly proud of this paper. To greatly simplify, we developed a way to model check the rules in OOAnalyzer. It's been incredibly effective at finding problems in OOAnalyzer's rules. We found 27 soundness issues in OOAnalyzer, and two in VirtAnalyzer, a competing C++ abstraction recovery system.
Unfortunately, the journey to publication for this paper has been long and bumpy. It is, admittedly, a fairly niche topic. But I also think it has some interesting ideas that could be applied more generally to other reverse engineering systems. In particular, I think that much of what we call "binary analysis" is actually "compiled executable analysis" in disguise. In other words, our binary analyses are often making (substantial!) assumptions about how compilers work, such as the calling conventions that are used, and without these assumptions they do not work. Our paper provides a systematic way to encode and refine these assumptions, and validate whether underlying analyses are correct under the assumptions. My hope is that in future work, we are able to demonstrate how to apply this overall approach to more traditional binary analyses. I personally think that static binary analysis without such reasonable simplifying assumptions is impractical, so we need more techniques like this to help analyze compiled executables.
Although I'm proud of the problems we discovered in OOAnalyzer, I'm also a bit disappointed in the practical impact. My hope was that when we found and fixed soundness problems in OOAnalyzer's rules, it would generally improve the performance of OOAnalyzer on real-world binaries. However, we found that in general this was not true. In fact, in some cases, fixing soundness problems actually made OOAnalyzer perform worse on real-world binaries! I think this highlights that there is a trade-off between soundness and accuracy in binary analysis. In order to be sound, the system can never make mistakes. We may need to make a rule more conservative, even if it almost never poses a problem in practice. However, in order to maximize accuracy, the system must optimize for the most common cases, even if it means that it will occasionally make mistakes.
SURE Workshop
SURE, the Workshop on Software Understanding and Reverse Engineering, is a new workshop colocated with ACM CCS this year. In addition to presenting our paper, I had the honor of participating in a panel on "Modern Software Understanding" alongside Fish Wang and Steffen Enders. The first SURE was a resounding success, and I'm eager to see how it evolves in the coming years!

🎉 New Research Published at DIMVA 2025
I'm excited to announce that "Quantifying and Mitigating the Impact of Obfuscations on Machine-Learning-Based Decompilation Improvement" has been published at the 2025 Conference on Detection of Intrusions and Malware & Vulnerability Assessment (DIMVA 2025)!
The Research Team
This work was primarily conducted by Deniz Bölöni-Turgut—a bright undergraduate at Cornell University—as part of the REU in Software Engineering (REUSE) program at CMU. She was supervised by Luke Dramko from our research group.
What We Investigated
This paper tackles an important question in the evolving landscape of AI-powered reverse engineering: How do code obfuscations impact the effectiveness of these ML-based approaches? In the real world, adversaries often employ obfuscation techniques to make their code harder to analyze by reverse engineers. Although these obfuscation techniques were not designed with machine learning in mind, they can significantly modify the code, which raises the question of whether they could hinder the performance of ML models, which are currently trained on unobfuscated code.
Key Findings
Our research provides important quantitative insights into how obfuscations affect ML-based decompilation:
-
Obfuscations do negatively impact ML models: We demonstrated that semantics-preserving transformations that obscure program functionality significantly reduce the accuracy of machine learning-based decompilation tools.
-
Training on obfuscated code helps: Our experiments show that training models on obfuscated code can partially recover the lost accuracy, making the tools more resilient to obfuscation techniques.
-
Consistent results across multiple models: We validated our findings across three different state-of-the-art models from the literature—DIRTY, HexT5, and VarBERT—suggesting that our findings generalize.
-
Practical implications for malware analysis: Since obfuscations are commonly used in malware, these findings are directly applicable to improving real-world binary analysis scenarios.
This work represents an important step forward in making ML-based decompilation tools more resilient against the obfuscation techniques commonly encountered in real-world binary analysis scenarios. As the field continues to evolve, understanding these vulnerabilities and developing robust solutions will be crucial for maintaining the effectiveness of AI-powered security tools.
Read More
Want to know more? Download the complete paper.
🎉 New Research Published at DSN 2025
I'm excited to announce that "A Human Study of Automatically Generated Decompiler Annotations" has been published at the 2025 IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2025)!
The Research Team
This work represents the culmination of Jeremy Lacomis's Ph.D. research, alongside our fantastic collaborators:
- Vanderbilt University: Yuwei Yang, Skyler Grandel, and Kevin Leach
- Carnegie Mellon University: Bogdan Vasilescu and Claire Le Goues
What We Studied
This paper investigates a critical question in reverse engineering: Do automatically generated variable names and type annotations actually help human analysts understand decompiled code?
Our study built upon DIRTY, our machine learning system that automatically generates meaningful variable names and type information for decompiled binaries. While DIRTY showed promising technical results, we wanted to understand its real-world impact on human reverse engineers.
Key Findings
- Surprisingly, the annotations did not significantly improve participants' task completion speed or accuracy
- This challenges assumptions about the direct correlation between code readability and task performance
- Participants preferred code with annotations over plain decompiled output
Read More
Interested in the full methodology and detailed results? Download the complete paper to dive deeper into our human study design, statistical analysis, and implications for future decompilation tools.
Many people seem to be unaware that decompilers have a decompilation export feature, which is particularly beneficial when you are trying to parse or recompile decompiled code.
Ghidra
Here is a random function from /bin/ls that I decompiled using Ghidra, and simply copied the output from the decompilation window:
void FUN_0010b1b0(undefined8 *param_1,undefined8 *param_2)
{
char *__s;
char *__s_00;
int iVar1;
char *__s1;
char *__s2;
int *piVar2;
__s = (char *)*param_2;
__s1 = strrchr(__s,0x2e);
__s_00 = (char *)*param_1;
__s2 = strrchr(__s_00,0x2e);
if (__s2 == (char *)0x0) {
__s2 = "";
}
if (__s1 == (char *)0x0) {
__s1 = "";
}
piVar2 = __errno_location();
*piVar2 = 0;
iVar1 = strcoll(__s1,__s2);
if (iVar1 == 0) {
strcoll(__s,__s_00);
return;
}
return;
}This code does not compile.
gcc -c a.c
a.c:1:19: error: unknown type name ‘undefined8’
1 | void FUN_0010b1b0(undefined8 *param_1,undefined8 *param_2)
| ^~~~~~~~~~
a.c:1:39: error: unknown type name ‘undefined8’
1 | void FUN_0010b1b0(undefined8 *param_1,undefined8 *param_2)
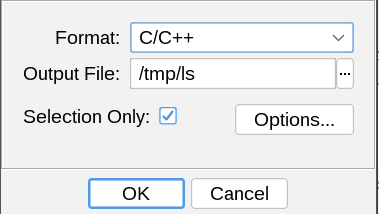
| ^~~~~~~~~~However, we can use Ghidra's decompiler exporter to decompile the function AND emit a header file that will define the types and declare the functions used in the decompiled code. Unfortunately, this is a little bit awkward to do for one function. I suggest the following process:
- In the CodeBrowser, select the function you want to decompile in the Listing (disassembly) window.
- In the CodeBrowser, navigate to File → Export Program.
- Select "C/C++" as the Format.
- Ensure that the "Selection Only" checkbox is checked.
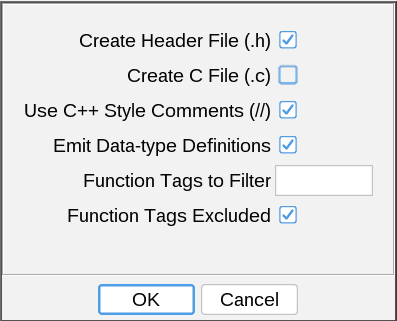
- In the Options dialog, check both the "Create Header File (.h)" and "Create C File (.c)" options.
- Click OK.
This will create a decompiled source file ls.c containing type definitions for types used in the decompiled code, such as undefined8.
And if you try to compile the generated ls.c file, it will compile successfully:
gcc -c ls.c
ls.c: In function ‘FUN_0010b1b0’:
ls.c:630:10: warning: implicit declaration of function ‘strrchr’ [-Wimplicit-function-declaration]
630 | __s1 = strrchr(__s,0x2e);
| ^~~~~~~
ls.c:1:1: note: include ‘<string.h>’ or provide a declaration of ‘strrchr’
+++ |+#include <string.h>
1 | typedef unsigned char undefined;
ls.c:630:10: warning: incompatible implicit declaration of built-in function ‘strrchr’ [-Wbuiltin-declaration-mismatch]
630 | __s1 = strrchr(__s,0x2e);
| ^~~~~~~
ls.c:630:10: note: include ‘<string.h>’ or provide a declaration of ‘strrchr’
ls.c:639:12: warning: implicit declaration of function ‘__errno_location’ [-Wimplicit-function-declaration]
639 | piVar2 = __errno_location();
| ^~~~~~~~~~~~~~~~
ls.c:639:10: warning: assignment to ‘int *’ from ‘int’ makes pointer from integer without a cast [-Wint-conversion]
639 | piVar2 = __errno_location();
| ^
ls.c:641:11: warning: implicit declaration of function ‘strcoll’ [-Wimplicit-function-declaration]
641 | iVar1 = strcoll(__s1,__s2);
| ^~~~~~~Hurray!
This is slightly oversimplified. You can see the compiler's warnings that we did not have declarations for strrchr, __errno_location, and strcoll. Ghidra can generate these declarations, but didn't because we used the "Selection Only" option. To get these declarations, you can use an approach like the following:
- Use "Export Program" to export the entire program. Under the "Options" dialog, check only the "Create Header File (.h)" option.
- Use "Export Program" to export only the function you care about, but this time check only the "Create C File (.c)" option.
- Remove type definitions from the generated C file, and instead include the generated header file.
- Cross your fingers.
Unfortunately, this header file does not always compile. Here are some errors that I obtained when trying to compile the header for /bin/ls:
In file included from FUN_0010b1b0.c:1:
FUN_0010b1b0.h:671:6: warning: conflicting types for built-in function ‘__snprintf_chk’; expected ‘int(char *, long unsigned int, int, long unsigned int, const char *, ...)’ [-Wbuiltin-declaration-mismatch]
671 | void __snprintf_chk(void);
| ^~~~~~~~~~~~~~
FUN_0010b1b0.h:682:5: error: ‘sigaction’ redeclared as different kind of symbol
682 | int sigaction(int __sig,sigaction *__act,sigaction *__oact);
| ^~~~~~~~~
FUN_0010b1b0.h:294:26: note: previous declaration of ‘sigaction’ with type ‘sigaction’
294 | typedef struct sigaction sigaction, *Psigaction;
| ^~~~~~~~~
FUN_0010b1b0.h:695:6: warning: conflicting types for built-in function ‘dcgettext’; expected ‘char *(const char *, const char *, int)’ [-Wbuiltin-declaration-mismatch]
695 | void dcgettext(void);
| ^~~~~~~~~
[truncated]This is probably because Ghidra's type manager includes multiple definitions for
some types, such as sigaction. I have opened a Ghidra
issue for these
problems. Hopefully the Ghidra developers will commit to fixing these problems
in the header file, since it would significantly improve the usability of the
decompiler output.
Here is a ghidra-scala-loader script that can do the above steps for you from the command line.
Hex-Rays
IDA/Hex-Rays has a similar feature, but it is much more straightforward. Simply select File → Create C File, and it will generate a C file that includes all the necessary type definitions and function declarations. It does include defs.h, which is a file that contains type definitions for Hex-Rays. You can find that in the Hex-Rays SDK or elsewhere.
Can existing neural decompiler artifacts be used to run on a new example? Here are some notes on the current state of the art. I assign each decompiler a score from 0 to 10 based on how easy it is to use the publicly available artifacts to run on a new example.
SLaDe: 2/10
SLaDe has a publicly released replication artifact but there are several problems that prevent it from being used on new examples:
- The models are trained on assembly code produced from compilers rather than disassemblers. This is probably minor.
- More problematically, SLaDe uses IO testcases during beam search to help detect the best candidate. It can be used without these, but the results will be worse. SLaDe does not contain a mechanism for producing testcases for new examples.
Below is a quote from a private conversation with the author:
You are right that IO are somehow used to select in the beam search, in the sense that we report pass@5. They are not strictly required to get the outputs though.
The link you sent is for the program synthesis dataset. In this one, IO generation was programmatic but still kind of manual, I don't think it would be feasible to automatically generate the props file in the general case. For the Github functions, we have a separate repo that automatically generates IO tests, but those are randomly generated and the quality depends on each case. If I had to redo now, I would ask an LLM to generate unit tests! I can give you access to the private repo we used to automatically generate the IO examples for the general case if you wish, but now I'd do it with LLMs rather than randomly.
LLM4Decompile: 9/10
LLM4Decompile has published model files on HuggingFace that can easily be used to run on new examples. I created a few HuggingFace Spaces for testing.
resym: 2/10
resym has a publicly released replication artifact. Unfortunately, as of February 2025, the artifact is missing the "prolog-based inference system for struct layout recovery" which is the key contribution of the paper. Thus it is not possible to run resym on new examples.
DeGPT: 8/10
DeGPT has a publicly released GitHub repository. I'm largely going on memory, but I used it previously on new examples and it was relatively easy to use. I did have to file a few PRs though.
In Part 1, we showed that tool-calling agents built using open source LLMs and LangChain almost universally performed poorly. They demonstrated strange behaviors such as responding to "Hello." by making non-sensical tool calls. In this blog post, we will try to determine why this happened.
Rather than investigating every model at once, in this blog post I'm going to focus my effort on Llama 3.2.
Hidden: Setup
Hidden: Setup
!pip install langgraph~=0.2.53 langchain-ollama langchain-huggingface python-dotenv
!pip install httpx==0.27.2 # temp
!apt-get install -y jq
debug = False
sample_size = 100
num_ctx = 8192from langchain_core.tools import tool
from langchain import hub
from langchain_core.messages import AIMessageChunk, HumanMessage@tool
def foobar(input: int) -> int:
"""Computes the foobar function on input and returns the result."""
return input + 2
tools = [foobar]from langgraph.prebuilt import create_react_agent
def react_chat(prompt, model):
agent_executor = create_react_agent(model, tools)
response = agent_executor.invoke({"messages": [("user", prompt)]})
return response['messages'][-1].content, responseHere we install ollama.
!ollama 2>/dev/null || curl -fsSL https://ollama.com/install.sh | shMake sure the ollama server is running.
!ollama -v
!ollama ps 2>/dev/null || (setsid env OLLAMA_DEBUG=1 nohup ollama serve &)
!ollama pull llama3.2 2>/dev/nullbasic_tool_question = "Please evaluate foobar(30)"
def q1(model):
last_msg, _ = react_chat(basic_tool_question, model=model)
r = "32" in last_msg
if not r and debug:
print(f"q1 debug: {last_msg}")
return rfrom langchain_core.messages import ToolMessage
basic_arithmetic_question = "What is 12345 - 102?"
greeting = "Hello!"
def q2a(model):
_, result = react_chat(basic_arithmetic_question, model=model)
return not any(isinstance(msg, ToolMessage) for msg in result['messages'])
def q2b(model):
_, result = react_chat(greeting, model=model)
return not any(isinstance(msg, ToolMessage) for msg in result['messages'])
def q2(model):
return q2a(model) and q2b(model)def q3a(model):
result = model.invoke(basic_arithmetic_question)
return "12243" in result.content
def q3b(model):
last_msg, _ = react_chat(basic_arithmetic_question, model=model)
r = "12243" in last_msg
if not r and debug:
print(f"q3b debug: {last_msg}")
return "12243" in last_msg
def q3(model):
# q3a ==> q3b: If q3a, then q3b ought to be true as well.
r = not q3a(model) or q3b(model)
return rdef q4(model):
last_msg, _ = react_chat(greeting, model=model)
c1 = any(w in last_msg for w in ["Hi", "hello", "Hello", "help you", "Welcome", "welcome", "Greeting", "assist"])
c2 = any(w in last_msg for w in ["None of the"])
r = c1 and not c2
#if not r:
if debug: print(f"q4 debug: c1={c1} c2={c2} r={r} greeting? {last_msg}")
return rfrom tqdm.notebook import tqdm
from termcolor import colored
def do_bool_sample(fun, n=10, *args, **kwargs):
try:
# tqdm here if desired
return sum(fun(*args, **kwargs) for _ in (range(n))) / n
except Exception as e:
print(e)
return 0.0
def run_experiment(model, name, n=10):
do = lambda f: do_bool_sample(f, model=model, n=n)
d = {
"q1": do(q1),
"q2": do(q2),
"q3": do(q3),
"q4": do(q4),
"n": n,
"model": name
}
d['total'] = d['q1'] + d['q2'] + d['q3'] + d['q4']
return d
def print_experiment(results):
name = results['model']
print(f"Question 1: Can the react agent use a tool correctly when explicitly asked? ({name}) success rate: {results['q1']}")
print(f"Question 2: Does the react agent invoke a tool when it shouldn't? ({name}) success rate: {results['q2']}")
print(f"Question 3: Does the react agent lose the ability to answer questions unrelated to tools? ({name}) success rate: {results['q3']}")
print(f"Question 4: Does the react agent lose the ability to chat? ({name}) success rate: {results['q4']}")
def run_and_print_experiment(model, name, **kwargs):
results = run_experiment(model, name, **kwargs)
print_experiment(results)
return resultsQuantization
You probably know that modern neural networks can be pretty large, and that is why special GPUs with lots of memory are in high demand right now. So how are we able to run some of these models on our computers, which don't have these special GPUs, using Ollama?
One reason is because Ollama uses quantized models, which are numerically compressed to use less memory. For example, the original Llama 3.2-3b-Instruct model uses bfloat16 tensors which require 16-bits to store each parameter. On Ollama's Llama 3.2 model page, you can see the quantization is listed as Q4_K_M. At a high-level, this squeezes each 16-bit parameter down to 4-bits. And somehow it still works!
Or does it? Maybe this is why our tool-callling doesn't work?
One simple way to test this is to evaluate a quantized version versus a non-quantized version. Luckily, this repository on HuggingFace happens to have both quantized and non-quantized models in a format that Ollama can process. So we can evaluate both of them using Ed's Really Dumb Tool-calling Benchmark ™️ that I introduced in Part 1.
from langchain_ollama import ChatOllama
quant_models = [
"hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:F16", # non-quantized
"hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:Q4_K_M", #quantized
]
for m in quant_models:
print(f"Model: {m}")
!ollama pull {m} 2>/dev/null
r = run_and_print_experiment(ChatOllama(model=m, num_ctx=num_ctx), m, n=sample_size)
print(r)Model: hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:F16
Question 1: Can the react agent use a tool correctly when explicitly asked? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:F16) success rate: 0.91
Question 2: Does the react agent invoke a tool when it shouldn't? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:F16) success rate: 0.0
Question 3: Does the react agent lose the ability to answer questions unrelated to tools? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:F16) success rate: 0.36
Question 4: Does the react agent lose the ability to chat? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:F16) success rate: 0.12
{'q1': 0.91, 'q2': 0.0, 'q3': 0.36, 'q4': 0.12, 'n': 100, 'model': 'hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:F16', 'total': 1.3900000000000001}
Model: hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:Q4_K_M
Question 1: Can the react agent use a tool correctly when explicitly asked? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:Q4_K_M) success rate: 0.99
Question 2: Does the react agent invoke a tool when it shouldn't? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:Q4_K_M) success rate: 0.0
Question 3: Does the react agent lose the ability to answer questions unrelated to tools? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:Q4_K_M) success rate: 0.51
Question 4: Does the react agent lose the ability to chat? (hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:Q4_K_M) success rate: 0.06
{'q1': 0.99, 'q2': 0.0, 'q3': 0.51, 'q4': 0.06, 'n': 100, 'model': 'hf.co/prithivMLmods/Llama-3.2-3B-Instruct-GGUF:Q4_K_M', 'total': 1.56}
Both models do poorly. In fact, the quantized version does slightly better.
Conclusion: Quantization is probably not the problem.
Prompt Templates
Behind the scenes, LLMs need to be prompted in a very specific format to work well. HuggingFace dubs this problem the silent performance killer. In response, they created "chat templates" which codify the format and live alongside the model to avoid any ambiguity. Note: I call these "prompt templates".
We haven't had to worry about prompt templates at all, because Ollama has been taking care of templating for us. Maybe its prompt templates are problematic?
To test this theory, we're going to build some code to query Ollama but without using Ollama to format the prompt for us. There are two purposes for this:
-
We will learn a bit how tool calling works and how it interacts with prompt templates. I have a suspicion that prompt templates have something to do with the problem.
-
We will avoid a lot of code that has been hiding behind abstraction. This is the downside of abstraction: it makes things easier to build, but it's harder to understand where the blame might lie when something fails.
Llama 3.2 Based Prompt
Let's start by examining the prompt template recommended for Llama 3.2, which is this template for zero-shot function calling from the llama-models repository. We'll talk more about this later, but Meta actually publishes conflicting prompt templates in different locations! So to be clear, this is the llama-models Llama 3.2 prompt template.
Here is the example from that page:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function,
also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
[
{
"name": "get_weather",
"description": "Get weather info for places",
"parameters": {
"type": "dict",
"required": [
"city"
],
"properties": {
"city": {
"type": "string",
"description": "The name of the city to get the weather for"
},
"metric": {
"type": "string",
"description": "The metric for weather. Options are: celsius, fahrenheit",
"default": "celsius"
}
}
}
}
]<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the weather in SF and Seattle?<|eot_id|><|start_header_id|>assistant<|end_header_id|>It's worth adding a few notes here. Modern LLMs are implemented as chat models, which means that they expect a conversation in the form of a list of messages that are sent by various roles. The primary roles are the user and the assistant. But we can also see that there are system messages, which are hidden instructions that are sent to the LLM. They provide instructions on how the LLM should behave. In this prompt template, we can see that it also specifies how and when the LLM should interact with tools.
On the same page is an example of the format in which the model should respond:
[get_weather(city='San Francisco', metric='celsius'), get_weather(city='Seattle', metric='celsius')]<|eot_id|>Let's code this up and try it out.
llama_32_example_funs = """[
{
"name": "get_weather",
"description": "Get weather info for places",
"parameters": {
"type": "dict",
"required": [
"city"
],
"properties": {
"city": {
"type": "string",
"description": "The name of the city to get the weather for"
},
"metric": {
"type": "string",
"description": "The metric for weather. Options are: celsius, fahrenheit",
"default": "celsius"
}
}
}
}
]"""
# https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/text_prompt_format.md#input-prompt-format-1
def llama_32_prompt_template(user, funs=llama_32_example_funs):
return """<|start_header_id|>system<|end_header_id|>
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function,
also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
%s<|eot_id|><|start_header_id|>user<|end_header_id|>
%s<|eot_id|><|start_header_id|>assistant<|end_header_id|>""" % (funs, user)print(llama_32_prompt_template("What is the weather in new york?", funs=llama_32_example_funs))<|start_header_id|>system<|end_header_id|>
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function,
also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
[
{
"name": "get_weather",
"description": "Get weather info for places",
"parameters": {
"type": "dict",
"required": [
"city"
],
"properties": {
"city": {
"type": "string",
"description": "The name of the city to get the weather for"
},
"metric": {
"type": "string",
"description": "The metric for weather. Options are: celsius, fahrenheit",
"default": "celsius"
}
}
}
}
]<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the weather in new york?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Looks good. Now we need some code to send the request to the Ollama API.
import json
def build_ollama_request(full_prompt, model="llama3.2"):
return f"""{{
"model": \"{model}\",
"prompt": {json.dumps(full_prompt)},
"raw": true,
"stream": false
}}
"""
def build_ollama_request_from_userprompt(user, template, funs=None, **kwargs):
return build_ollama_request(template(user, funs), **kwargs)
def send_request(full_request):
open("req", "w").write(full_request)
!curl -s http://localhost:11434/api/generate --data-ascii "@req" | jq -M '.response'
def send_userprompt(user, **kwargs):
request = build_ollama_request_from_userprompt(user, **kwargs)
send_request(request)
# A few sample prompts...
prompts = [
"Use tools to find the weather in new york", # llama 3.2 example
"Use tools to get latest trending songs", # llama 3.1 example
basic_tool_question, # Please evaluate foobar(30)
greeting, # Hello!
basic_arithmetic_question # What is 12345 - 102?
]
def try_prompts(**kwargs):
for p in prompts:
print(f"Prompt: {p}\nResponse: ", end="")
send_userprompt(p, **kwargs)
print()In the list of example prompts, there are three tool calling examples. We will
be passing along the get_weather tool definition. Obviously, commonsense tells
us that the model should not attempt to list trending songs or evaluate
foobar(30) using get_weather. Let's see how it does.
for _ in range(1):
try_prompts(funs=llama_32_example_funs, template=llama_32_prompt_template, model="llama3.2")Prompt: Use tools to find the weather in new york Response: "\n\n[get_weather(city='New York')]" Prompt: Use tools to get latest trending songs Response: "\n\n[get_weather(city='trending songs', metric='') ]" Prompt: Please evaluate foobar(30) Response: "\n\n[]" Prompt: Hello! Response: "\n\nNothing to see here. Would you like to ask a question or request a function call?" Prompt: What is 12345 - 102? Response: "\n\n[]"
On Sunday, the weather is going to be sunny with a chance of rain in the legendary city of "Trending Songs".
Overall, this is pretty disappointing. The model appears overly eager to call tools, even when it makes no sense, such as calling get_weather on the city of "trending songs". Oops. And it often responds unnaturally to "Hello!". It doesn't respond at all to the arithmetic or foobar questions.
Llama 3.1 Based Prompt
Llama 3.2 is actually compatible with the Llama 3.1 prompt format for tool calling, so next let's try the llama-models Llama 3.1 prompt template. Below is the example from that page.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Environment: ipython
Cutting Knowledge Date: December 2023
Today Date: 21 September 2024
You are a helpful assistant.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Answer the user's question by making use of the following functions if needed.
If none of the function can be used, please say so.
Here is a list of functions in JSON format:
{
"type": "function",
"function": {
"name": "trending_songs",
"description": "Returns the trending songs on a Music site",
"parameters": {
"type": "object",
"properties": [
{
"n": {
"type": "object",
"description": "The number of songs to return"
}
},
{
"genre": {
"type": "object",
"description": "The genre of the songs to return"
}
}
],
"required": ["n"]
}
}
}
Return function calls in JSON format.<|eot_id|><|start_header_id|>user<|end_header_id|>
Use tools to get latest trending songs<|eot_id|><|start_header_id|>assistant<|end_header_id|>Notice that the Llama 3.2 and 3.1 prompt templates have very little in common!
Let's code up the Llama 3.1 prompt and test it out.
llama_31_example_funs = """{
"type": "function",
"function": {
"name": "trending_songs",
"description": "Returns the trending songs on a Music site",
"parameters": {
"type": "object",
"properties": [
{
"n": {
"type": "object",
"description": "The number of songs to return"
}
},
{
"genre": {
"type": "object",
"description": "The genre of the songs to return"
}
}
],
"required": ["n"]
}
}
}
"""
# https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/prompt_format.md#input-prompt-format-5
def llama_31_prompt_template(user, funs=llama_31_example_funs):
return """<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Environment: ipython
Cutting Knowledge Date: December 2023
Today Date: 21 September 2024
You are a helpful assistant.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Answer the user's question by making use of the following functions if needed.
If none of the function can be used, please say so.
Here is a list of functions in JSON format:
%s
Return function calls in JSON format.<|eot_id|><|start_header_id|>user<|end_header_id|>
%s<|eot_id|><|start_header_id|>assistant<|end_header_id|>
""" % (funs, user)
Now we'll run the sample prompts again, but this time we'll use the Llama 3.1 example function trending_songs rather than get_weather. As before, commonsense tells us that we can't use trending_songs to predict the weather or compute foobar(30). Let's see how it does.
for _ in range(1):
try_prompts(funs=llama_31_example_funs, template=llama_31_prompt_template, model="llama3.2")Prompt: Use tools to find the weather in new york
Response: "I can't directly use the provided function to find the weather in New York as it is a location-based API and the given function is for getting trending songs, not weather information."
Prompt: Use tools to get latest trending songs
Response: "{\"type\": \"function\", \"name\": \"trending_songs\", \"parameters\": {\"n\": \"10\"}}"
Prompt: Please evaluate foobar(30)
Response: "Since there is no `foobar` function available, the answer is: None"
Prompt: Hello!
Response: "Hello! How can I assist you today?"
Prompt: What is 12345 - 102?
Response: "I'm not aware of any function that can perform this calculation. The functions provided only include the `trending_songs` function, which is used to retrieve trending songs based on a specific number of songs and genre. It does not include arithmetic operations like subtraction. If you need help with a different type of calculation, please let me know!"
These responses seems greatly improved compared to the Llama 3.2 prompt we tried. The response to a greeting is more natural. It also didn't do silly things like stuffing "trending songs" into the get_weather function calls.
The only consistent problem I can see is that it didn't even try to answer the arithmetic question. Let's see if we can fix that by slightly tweaking the wording of the prompt with the following diff:
-Answer the user's question by making use of the following functions if needed.
-If none of the function can be used, please say so.
+Help and converse with the user. If and only if the user asks a question that
+is relevant to one of the following functions, make use of them. If none of
+the functions can be used, answer the query as best you can.def llama_31_custom_prompt_template(user, funs=llama_31_example_funs):
return """<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Environment: ipython
Cutting Knowledge Date: December 2023
Today Date: 21 September 2024
You are a helpful assistant.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Help and converse with the user. If and only if the user asks a question that
is relevant to one of the following functions, make use of them. If none of
the functions can be used, answer the query as best you can.
Here is a list of functions in JSON format:
%s
Return function calls in JSON format.<|eot_id|><|start_header_id|>user<|end_header_id|>
%s<|eot_id|><|start_header_id|>assistant<|end_header_id|>
""" % (funs, user)
for _ in range(1):
try_prompts(funs=llama_31_example_funs, template=llama_31_custom_prompt_template, model="llama3.2")Prompt: Use tools to find the weather in new york
Response: "Since the provided function `trending_songs` is related to music and not weather, I'll answer your question as best I can.\n\nAccording to current information, New York's weather can be quite varied depending on the time of year. In general, winters are cold and snowy, while summers are hot and humid. Springs and autumns are generally mild.\n\nIf you're looking for more specific or up-to-date weather information, I recommend checking a reliable weather website or app, such as AccuWeather or Weather.com, which can provide more accurate and current forecasts for New York City and surrounding areas."
Prompt: Use tools to get latest trending songs
Response: "Here is a function call in JSON format that uses the `trending_songs` function to get the latest trending songs:\n\n```\n{\n \"type\": \"function\",\n \"name\": \"trending_songs\",\n \"parameters\": {\n \"n\": \"10\"\n }\n}\n```"
Prompt: Please evaluate foobar(30)
Response: "Unfortunately, I don't have any information about a `foobar` function. Could you please provide more context or details about this function? Is it defined somewhere else that I can access? Or would you like me to try and infer what the `foobar` function might do based on its name?"
Prompt: Hello!
Response: "Hello! How can I assist you today?"
Prompt: What is 12345 - 102?
Response: "Since no specific function can be used for this question, I'll answer it directly:\n\nThe result of subtracting 102 from 12345 is 12343."
This seemed to work really well if you ignore the fact that it got the subtraction wrong 🤣
What prompt template is Ollama using?
So we found a prompt template that appears to be working well. Let's try to make Ollama use that prompt template. To start, let's investigate what prompt template it's using "by default".
def get_raw_prompt():
template = !cat nohup.out | fgrep "chat request" | sed -e 's/.*prompt="\(.*\)"/\1/'
return [s.encode().decode('unicode_escape') for s in template]
!ollama pull llama3.2 2>/dev/null
!>nohup.out # Truncate ollama output
response = react_chat(greeting, model=ChatOllama(model="llama3.2", num_ctx=num_ctx))
print(get_raw_prompt()[0])<|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
When you receive a tool call response, use the output to format an answer to the orginal user question.
You are a helpful assistant with tool calling capabilities.<|eot_id|><|start_header_id|>user<|end_header_id|>
Given the following functions, please respond with a JSON for a function call with its proper arguments that best answers the given prompt.
Respond in the format {"name": function name, "parameters": dictionary of argument name and its value}. Do not use variables.
{"type":"function","function":{"name":"foobar","description":"Computes the foobar function on input and returns the result.","parameters":{"type":"object","required":["input"],"properties":{"input":{"type":"integer","description":""}}}}}
Hello!<|eot_id|><|start_header_id|>assistant<|end_header_id|>
That doesn't look like either of the prompt templates we used before, which both came from the llama-models repository. After a bit of google-fu, we can see that it originated from the Llama 3.1 "JSON based" tool calling documentation on the llama website. But it's not the same Llama 3.1 prompt template that we used from the llama-models repository.
This raises a few questions:
-
Why are there multiple prompt templates for Llama 3.1?
-
Which prompt template is best?
-
Why not use the prompt template for Llama 3.2, since we are using the Llama 3.2 model?
Let's start by answering the first two questions. In this github issue, a user notes that there are at least three different prompt templates for Llama 3.1:
A Meta employee states that the template in the llama-models repository is the correct one. Fortunately, that's what we have been using in this blog post. (It's almost as if I knew this in advance!) But Ollama has been basing their template on the one from the model website. That seems problematic!
The last question, "Why not use the prompt format for Llama 3.2?" is pretty easy to answer as well. Llama 3.2's default prompt format responds using a pythonic function call syntax that Ollama can't parse. And, as we saw above when we tested it manually, the Llama 3.2 prompt anecdotally did not seem to work well anyway.
Let's build our own Ollama prompt template
Now that we identified a prompt template that seems to work pretty well, let's try to make Ollama use it.
To start, let's look at the default prompt template for the llama3.2 model in Ollama. We already saw the instantiated prompt, but now let's look at the template that Ollama uses to build the prompts. You can see this below, or on the Ollama website here.
<|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
{{ if .System }}{{ .System }}
{{- end }}
{{- if .Tools }}When you receive a tool call response, use the output to format an answer to the orginal user question.
You are a helpful assistant with tool calling capabilities.
{{- end }}<|eot_id|>
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 }}
{{- if eq .Role "user" }}<|start_header_id|>user<|end_header_id|>
{{- if and $.Tools $last }}
Given the following functions, please respond with a JSON for a function call with its proper arguments that best answers the given prompt.
Respond in the format {"name": function name, "parameters": dictionary of argument name and its value}. Do not use variables.
{{ range $.Tools }}
{{- . }}
{{ end }}
{{ .Content }}<|eot_id|>
{{- else }}
{{ .Content }}<|eot_id|>
{{- end }}{{ if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- else if eq .Role "assistant" }}<|start_header_id|>assistant<|end_header_id|>
{{- if .ToolCalls }}
{{ range .ToolCalls }}
{"name": "{{ .Function.Name }}", "parameters": {{ .Function.Arguments }}}{{ end }}
{{- else }}
{{ .Content }}
{{- end }}{{ if not $last }}<|eot_id|>{{ end }}
{{- else if eq .Role "tool" }}<|start_header_id|>ipython<|end_header_id|>
{{ .Content }}<|eot_id|>{{ if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- end }}
{{- end }}It's not just you. It really is hard to read. The above code is written in the Go template language. I recommend using this interactive editor to better understand how the template language works if you are interested.
At a high level, the prompt template takes a sequence of messages and converts it into a prompt for the model. Some important notes:
ToolCallsindicate the calls the model wants to make. Ollama infers these by parsing the model's responses.- The
toolrole contains the output of an executed tool. - The
userandassistantroles are self explanatory!
With a lot of trial and error in the interactive template editor, I converted our earlier template into the Ollama format:
<|start_header_id|>system<|end_header_id|>
Environment: ipython
Cutting Knowledge Date: December 2023
Today Date: 21 September 2024
{{ if .System }}{{ .System }}
{{- end -}}
<|eot_id|>{{ if .Tools }}<|start_header_id|>user<|end_header_id|>
Help and converse with the user. If and only if the user asks a question that
is relevant to one of the following functions, make use of them. If none of
the functions can be used, answer the query as best you can.
Here is a list of functions in JSON format:
{{- range $.Tools }}
{{ . }}{{ end }}
Return function calls in JSON format.<|eot_id|>{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 }}
{{- if eq .Role "user" }}<|start_header_id|>user<|end_header_id|>
{{ .Content }}<|eot_id|>
{{- if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- else if eq .Role "assistant" }}<|start_header_id|>assistant<|end_header_id|>
{{- if .ToolCalls }}
<|python_tag|>{{- range .ToolCalls -}}
{"name": "{{ .Function.Name }}", "parameters": {{ .Function.Arguments }}}{{ end }}<|eom_id|>
{{- else }}
{{ .Content }}<|eot_id|>
{{- end }}
{{- else if eq .Role "tool" }}<|start_header_id|>ipython<|end_header_id|>
{{ .Content }}<|eot_id|>{{ if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- end }}
{{- end }}Now the big question -- does it actually work?
Does our new Ollama prompt template work as intended?
First, let's make a query and make sure that we get the right answer!
!>nohup.out # Truncate ollama output
!ollama pull ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized 2>/dev/null
response = react_chat(basic_tool_question, model=ChatOllama(model="ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized", num_ctx=num_ctx))
print(response[0])
assert "32" in response[0]The result of the foobar function when called with 30 as input is 32.
Second, let's take a peek at the prompt we sent to the LLM.
print(get_raw_prompt()[-1])<|start_header_id|>system<|end_header_id|>
Environment: ipython
Cutting Knowledge Date: December 2023
Today Date: 21 September 2024
<|eot_id|><|start_header_id|>user<|end_header_id|>
Help and converse with the user. If and only if the user asks a question that
is relevant to one of the following functions, make use of them. If none of
the functions can be used, answer the query as best you can.
Here is a list of functions in JSON format:
{"type":"function","function":{"name":"foobar","description":"Computes the foobar function on input and returns the result.","parameters":{"type":"object","required":["input"],"properties":{"input":{"type":"integer","description":""}}}}}
Return function calls in JSON format.<|eot_id|><|start_header_id|>user<|end_header_id|>
Please evaluate foobar(30)<|eot_id|><|start_header_id|>assistant<|end_header_id|>
<|python_tag|>{"name": "foobar", "parameters": {"input":30}}<|eom_id|><|start_header_id|>ipython<|end_header_id|>
32<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Looks good to me!
Alright, let's run it through Ed's Really Dumb Tool-calling Benchmark ™️. We'll run the original Llama 3.2 model in Ollama (llama3.2) and the Llama 3.1 tooling prompt too for comparison.
models = [
"llama3.2",
"ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt", # based on the llama 3.1 tooling prompt
"ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized", # our improved prompt
]
for m in models:
print(f"Testing model: {m}")
!ollama pull {m} 2>/dev/null
r = run_and_print_experiment(ChatOllama(model=m, num_ctx=num_ctx), m, n=sample_size)
print(r)Testing model: llama3.2
Question 1: Can the react agent use a tool correctly when explicitly asked? (llama3.2) success rate: 0.97
Question 2: Does the react agent invoke a tool when it shouldn't? (llama3.2) success rate: 0.0
Question 3: Does the react agent lose the ability to answer questions unrelated to tools? (llama3.2) success rate: 0.55
Question 4: Does the react agent lose the ability to chat? (llama3.2) success rate: 0.09
{'q1': 0.97, 'q2': 0.0, 'q3': 0.55, 'q4': 0.09, 'n': 100, 'model': 'llama3.2', 'total': 1.61}
Testing model: ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt
Question 1: Can the react agent use a tool correctly when explicitly asked? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt) success rate: 1.0
Question 2: Does the react agent invoke a tool when it shouldn't? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt) success rate: 0.15
Question 3: Does the react agent lose the ability to answer questions unrelated to tools? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt) success rate: 0.51
Question 4: Does the react agent lose the ability to chat? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt) success rate: 0.49
{'q1': 1.0, 'q2': 0.15, 'q3': 0.51, 'q4': 0.49, 'n': 100, 'model': 'ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt', 'total': 2.15}
Testing model: ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized
Question 1: Can the react agent use a tool correctly when explicitly asked? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized) success rate: 0.99
Question 2: Does the react agent invoke a tool when it shouldn't? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized) success rate: 0.99
Question 3: Does the react agent lose the ability to answer questions unrelated to tools? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized) success rate: 0.68
Question 4: Does the react agent lose the ability to chat? (ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized) success rate: 1.0
{'q1': 0.99, 'q2': 0.99, 'q3': 0.68, 'q4': 1.0, 'n': 100, 'model': 'ejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customized', 'total': 3.66}
The original Ollama prompt scored 1.61/4.0. The official Llama 3.1 tooling prompt scored 2.15/4.0, and my customized prompt scored 3.6/4.0. I'd say that is an improvement!
Coming Clean
I do want to come clean. I did not create that prompt template in one try. It actually took many days of experimenting and debugging.
(I find that this is often a dilemma when blogging. Keeping track of everything you did is difficult, time-consuming, and often not that interesting.)
Many things went wrong along the way, but here are a few issues that I remember:
Environment: ipythonis supposed to be for enabling Llama's code interpreter, which we aren't using, but I wasn't able to get the Llama 3.1 prompt to work well without it.- Llama has some weird rules for when to use
<|eom_id|>vs.<|eot_id|>, and I got them wrong. As a result, even though the initial prompt was correct, Llama could not "parse" the results to correctly build the final message. - In Llama 3.1 prompts, when the model responds with a tool call, it is supposed to be prefixed with
<|python_tag|>. Somewhat oddly (in my opinion), existing Ollama prompts "rebuild" the tool call response from the parsed values, rather than using the original message. As a result, I had to add in the<|python_tag|>or the model would become confused and struggle to build the final message to the user. - In one template, I added an extra newline, and this caused a notable decrease in performance! Yes, models really are that sensitive.
Recap
Let's recap all the things we had to do to get to this point:
-
We used the Llama 3.1 prompt template from the llama-models repository and NOT the Llama 3.1 website, which is Ollama's prompt was based on.
-
We modified the wording of the prompt to improve its responses to non-tool-calls like greetings and arithmetic.
And this was all just to improve the performance of one single model. I'm tired, aren't you?
Conclusion
Prompts are definitely part of the reason why building tool calling agents did not work in Part 1. But HuggingFace raised the alarm about this a long time ago! So what went wrong?
What went wrong?
Now that tool-calling is becoming more popular, prompt templates must be considered a fundamental part of a model, just like the weights. The reason for this is simple: the model developer is the only entity who has a clear incentive to ensure that their model works as well as possible. Downstream consumers like Ollama do not have an incentive to make sure that prompt templates work as well as possible. Unfortunately for Llama, Meta did not treat the prompt templates as a fundamental part of the model. Meta did a poor job of documenting the prompt templates: the example-based documentation is vague, and the multiple conflicting sources of information further confused the issue. So right off the bat, Llama models are not bundled with a clear prompt template.
Ollama did not help the situation. Instead of adopting an existing template format such as HuggingFace's, they decided to roll their own format based on Go templates. On one hand, this is a natural decision since Ollama is written in Go. But now someone has to write a new prompt template for every model on Ollama. Currently, it is the Ollama developers themselves who are creating these prompt templates. But as I mentioned above, there is a concerning incentive mismatch: the Ollama developers don't have an incentive to determine the best prompt format for every model. Here is a stark example where the Ollama developers have provided unhelpful and misleading responses when users reported that models were making non-sensical tool calls:
Don't bind tools if you don't want [the Llama model to make] a tool call.
Of course, as evidenced by this blog post, the real problem was that the Ollama developers themselves chose a prompt template that performed poorly on tool-calling. (I don't mean to beat up on the Ollama project. I think it's a great project! But they didn't help themselves out in this area.)
What can we do about it?
Standards
We really do need a standard for prompt templates. HuggingFace's chat template is a good start, but it is not perfect. While it describes how to format messages that should be sent to the model, it doesn't define how to parse the model's responses, which is equally important. As an example, I suspect that a major reason why Ollama's Llama 3.2 model used a Llama 3.1 prompt template is because Ollama's tool-call parser does not support the pythonic format used in the Llama 3.2 prompts. Parsing tool-calls is currently very ad-hoc.
Another problem with HuggingFace's chat templates is language compatibility. I suspect that part of the reason why Ollama chose to use their own template format is convenience. HuggingFace's chat templates are based on jinja2, which is a template language for python. But Ollama is written in Go. Perhaps we need a standard format that is more language agnostic.
Ollama
Ollama should either adopt the HuggingFace template format or create a tool that can convert HuggingFace templates to Ollama templates. The current system of manually converting templates is error prone and harmful.
Ollama should also add information to their model cards about which prompt templates they adopted and why. For example, the Llama 3.2 model card does not mention that the prompt template is based on the Llama 3.1 prompt format, or why.
Benchmarks
Benchmarks such as the Berkeley Function-Calling Leaderboard (BFCL) could also be doing more about the prompt problem. For Llama, it appears that, similar to the Ollama developers, the BFCL developers have simply chosen a prompt and implemented it. Llama 3.1 and 3.3 appear to be based on a Llama HuggingFace chat template while other versions use a generic prompt.
We don't know how or why they selected these prompts. As with the Ollama developers, there is an incentive mismatch: they don't have an incentive or responsibility to experiment. Perhaps there should be more incentive for model developers to fix the prompt templates in order to score better on the BFCL, but it doesn't seem like that is how things works today. Honestly, I don't understand why; I would think that Meta would be embarrassed that the Llama-3.2-3B-Instruct model only scores 5.25% on the BFCL in Overall Multi Turn Accuracy.
Llama
The Llama developers really need to do a better job documenting its prompt templates. The example-based "documentation" is vague. And more critically, there shouldn't be conflicting information. Even after they were notified about it, the problem remains. In the same github issue, it's clear that people can't reproduce Meta's experimental results either.
Closing Thoughts
We largely got to the bottom of the problems in Llama 3.2, but this was just one of many models that performed poorly. Are all of these models suffering from prompt template problems, or are there other problems as well? Stay tuned to find out.
TLDR
Better Ollama models for Llama 3.2 tool calling are available here:
ejschwar/llama3.2-better-prompts:llama3.1-tooling-promptis based on this Llama 3.1 promptejschwar/llama3.2-better-prompts:llama3.1-tooling-prompt-customizedis based on this Llama 3.1 prompt but slightly modifies the language to improve behavior on responding to queries unrelated to tools.
Given the recent change in government here in the US, I've been thinking a lot about my personal beliefs and values. As part of this process, I decided to write my own personal manifesto. I hope that even if I do not see eye to eye on political matters with all my neighbors and fellow citizens, we can find some common ground on the values that matter most to me.
As a reminder, everything on this blog is my own opinion and does not reflect the views of my employer or anyone else.
My Personal Manifesto
Life is inherently unequal, shaped by factors beyond our control—genetics, financial circumstances, and sheer luck. I feel that those who are fortunate bear a responsibility to help those who are not, and that principle should be a foundation of our society. A truly fair and compassionate world requires us to ensure that everyone, regardless of gender, race, or any other characteristic, is given a fair and equal chance. When some groups consistently achieve more success than others based on traits like skin color, it signals a deeper flaw in our society. Equality must be more than a principle—it must be a reality reflected in the systems and institutions that govern us.
Freedom is one of life’s most important values, but it should not come at the expense of others’ well-being. We should accept people as they are, reserving judgment only when someone’s actions cause real harm—discomfort, unease, or disagreement with someone’s identity, culture, or way of life does not constitute harm. Prejudice and bigotry, when disguised as "freedom of expression," should not be allowed to infringe upon others’ dignity and rights under the guise of tolerance.
In making political or social decisions, it is essential to think beyond our immediate reactions and consider the broader impact, including possible side effects. Policies must align with their stated goals and follow through on their commitments. For example, if a policy restricts abortion under the guise of protecting unborn children, it should also provide resources and support to ensure those children are cared for and supported after birth. Making a decision without committing to its consequences is irresponsible and ultimately harmful. True responsibility means considering all dimensions and consequences and committing to the outcomes of our choices.
A society grounded in truth and information is best equipped to address these challenges. Facts and science must take precedence over opinions or political agendas, ensuring our systems and policies are rooted in evidence rather than ideology. Truth is non-negotiable, and it must guide our decisions and perspectives. Science and evidence are the tools we use to uncover systemic injustices, evaluate the impacts of our actions, and create solutions that reflect reality, not rhetoric.
This manifesto is a call for a society that values truth, compassion, fairness, and foresight. It is a vision of a world where integrity, responsibility, and respect for all people guide our actions and our choices.
Powered with by Gatsby 5.0